Archives
now browsing by author
Signer un document sur Android devient enfin un jeu d’enfant

Signer un document numérique sur son smartphone a longtemps été une opération fastidieuse, nécessitant souvent le téléchargement d’applications tierces ou des manipulations peu pratiques. Pour mettre fin à cette situation, la firme de Mountain View a décidé d’intégrer une solution directement au cœur de son système d’exploitation mobile. Une nouvelle application, simplement baptisée « Signatures », est actuellement en cours de déploiement discret sur les appareils compatibles.
Comment cette nouvelle application fonctionne-t-elle ?
L’application « Signatures » n’est pas un logiciel classique que l’on télécharge depuis le Play Store. Il s’agit en réalité d’un composant système, distribué silencieusement par le biais des mises à jour système Google Play. Cette méthode de déploiement, indépendante des constructeurs, permet à Google d’équiper un large parc d’appareils, à condition qu’ils fonctionnent au minimum sous Android 12.
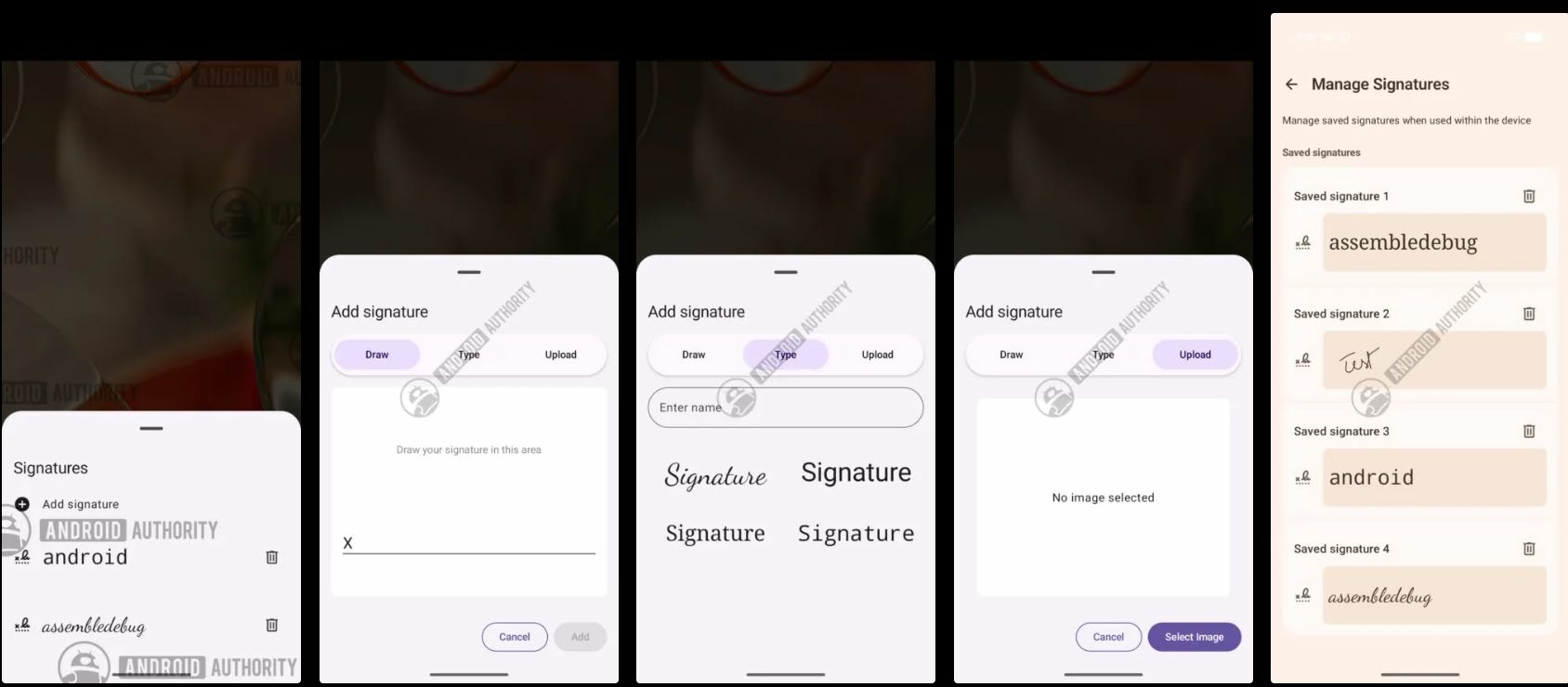
Crédits : Android Authority
Des modèles Pixel, Samsung et OnePlus ont déjà été aperçus avec cette nouvelle fonctionnalité. L’outil est conçu comme un véritable coffre-fort numérique permettant de centraliser et de gérer différentes versions de votre signature. Les applications compatibles pourront alors simplement puiser dans ce coffre pour vous proposer la signature adéquate, un peu à la manière du sélecteur de photos que l’on connaît déjà sur le système d’exploitation.
Quelles sont les options de création de signature disponibles ?
Pour s’adapter à tous les usages, l’application propose trois méthodes distinctes pour enregistrer une signature. La plus intuitive consiste à la dessiner directement sur l’écran tactile du smartphone, avec le doigt ou un stylet. Cette méthode reproduit fidèlement le geste manuscrit, offrant une solution rapide pour le système Android.
Une deuxième option permet de taper ses initiales (paraphe) ou son nom complet au clavier. L’application propose ensuite plusieurs polices de caractères pour donner un style manuscrit au texte saisi. Enfin, il est également possible d’importer une image, par exemple une photo d’une signature déjà apposée sur un document papier, pour la numériser et la stocker.

Quand cette fonctionnalité sera-t-elle pleinement opérationnelle ?
Bien que l’application soit déjà en cours de déploiement via la mise à jour système Google Play de juin, elle n’est pas encore totalement fonctionnelle. Pour l’instant, l’interface est accessible, mais l’intégration avec des documents PDF ou des services tiers comme DocuSign n’est pas encore active. L’application n’existe pas non plus de manière indépendante et doit être lancée manuellement via les paramètres système.
La firme de Mountain View n’a pas encore communiqué officiellement sur le calendrier ni sur les directives techniques pour les développeurs. Il faudra donc patienter un peu avant que cet outil soit pleinement intégré dans l’écosystème. Il est important de noter que cette solution gère des représentations graphiques et non des signatures électroniques certifiées à valeur juridique renforcée. Son but premier est la simplification et la commodité au quotidien.
Source : Signer un document sur Android devient enfin un jeu d’enfant
Comment faire un majuscule accentuée É, È, Ù, À, Ç sur Windows 11


À la rédaction de Frandroid, il y a quelques outils indispensables que l’on installe sur tous les ordinateurs. Il y a le correcteur orthographique Antidote, notre logiciel d’analyse Calman pour tester les écrans des smartphones, mais aussi quelque chose de bien plus simple : un petit outil pour mieux écrire en français avec un clavier AZERTY sous Windows.
Sur les PC sous Windows, la disposition des touches associée aux claviers AZERTY ne permet pas de taper certains caractères facilement : un Ù en majuscule, un È en majuscule, un « À », un « œ », ou encore les guillemets français que je viens d’utiliser. Il faut en général recourir aux codes ASCII avec des raccourcis assez complexes à mémoriser. Heureusement, une solution permet de se passer de ces raccourcis et d’avoir une disposition des touches réellement pensée pour notre langue.
Comment mettre un accent à une majuscule avec un raccourci clavier (É, È, Ù, À, Ç)
Si vous souhaitez simplement, et très occasionnellement, écrire une lettre majuscule ou un caractère spécial, il est possible d’utiliser des raccourcis clavier directement sous Windows sans aucune installation nécessaire.
Les majuscules accentuées en codes ASCII
La méthode sans installation, c’est d’utiliser le code ASCII. Pour faire simple, l’ASCII désigne le codage des caractères imprimables. À chaque caractère on donne un identifiant et cet identifiant est appelé par les logiciels pour écrire le caractère correspondant. Avec la touche Alt gauche enfoncée, il est possible d’inscrire manuellement ces caractères si on connait leur identifiant.
Voici la liste des principaux caractères en majuscule et le raccourci utilisant le code ASCII.
- À : Alt + 0192
- É : Alt + 0201
- È : Alt + 0200
- Ç : Alt + 0199
- Ù : Alt + 0217
Télécharger et installer le clavier français avec majuscules accentuées
On doit cet outil à Georges Plannelles qui le propose sur son site Skitiks en téléchargement. Il est gratuit, facile à installer et compatible avec toutes les versions de Windows depuis Windows XP jusqu’à Windows 11. Voici comment l’installer.
- Télécharger le clavier gratuit
- Dans le dossier de téléchargement, faire un clic droit sur le fichier « clavier_majuscules_accentuees.zip » puis choisir « extraire tout… »
- Dans le nouveau dossier, « clavier_majuscules_accentuees » créé, double cliquez sur « setup.exe » pour lancer l’installation
- Ignorer l’alerte Windows SmartScreen, le logiciel n’est pas assez connu pour passer le filtre correctement
")
")
Une fois le nouveau clavier installé, il va falloir configurer Windows 11 pour l’utiliser. Pour cela il y a plusieurs solutions. La première est tout simplement d’utiliser le raccourci « ALT + MAJ » pour basculer d’un clavier à l’autre. Alternativement, vous pouvez sélectionner le bon clavier en cliquant sur « FRA FR » dans la barre des tâches.
Dernière solution, se rendre dans les paramètres de Windows 10, à la rubrique « Heure et langue », puis dans l’onglet « langue » et choisir l’option « clavier » pour sélectionner notre nouveau clavier « Français (Majuscules accentuées) ».
")
")
")
")
")
Avec le nouveau clavier correctement configuré, il ne reste plus qu’à en apprendre les nouvelles fonctions.
Utiliser le clavier
Ce nouveau clavier est assez simple à prendre en main. Il suffit de retenir que la touche AltGr permet de choisir les touches alternatives propres au clavier. Pour le reste, le clavier suit les mêmes principes que le clavier AZERTY classique de Windows 10.

En y ajoutant la touche MAJ, on obtient encore de nouveaux caractères possibles.

Comment taper des majuscules accentuées É, È, Ù et À ?
Ainsi, pour taper la majuscule accentuée É, il suffit de faire : AltGr (pour prendre la touche alternative) + Maj (pour une majuscule) + « é ». Habituellement, cette combinaison devrait produire « 2 » qui partage la même touche que « 2 », mais comme on a appuyé sur la touche AltGr, c’est bien notre majuscule accentuée qui apparaît.
Même principe pour les autres majuscules.
- È : AltGr + Maj + è
- Ù : AltGr + Maj + ù
- À : AltGr + Maj + à
Comment taper des guillemets français ?
Les guillemets français « » sont très utilisés en français à la place des guillemets anglais ( ˝ ) souvent utilisés sur les supports numériques.
Avec le clavier, il suffit de faire la combinaison de touche suivante pour ouvrir les guillemets : AltGr + <. Pour les refermer, il faut appuyer sur AltGr + Maj + <.
Comment taper les caractères spéciaux comme œ, æ ou © ?
Ce clavier permet aussi de taper des caractères spéciaux couramment utilisés en français comme le graphème œ. Là encore, il suffit de taper Alt et la touche la plus susceptible d’être approprié. Voici quelques exemples.
- œ : Alt + o (Œ : Alt + Maj + o)
- æ : Alt + a (Æ : Alt + Maj + a)
- © : Alt + c
- ƒ : Alt + f
- ™ : Alt + t
C’est pour nous un petit outil très pratique et indispensable à installer sur Windows 11. Très simple à utiliser, il fait surtout gagner beaucoup de temps au quotidien.
Source : Comment faire un majuscule accentuée É, È, Ù, À, Ç sur Windows 11
Voiture électrique et canicule : voici nos astuces pour préserver votre batterie et votre autonomie


La canicule s’installe en France et, soyons honnêtes, vos voitures électriques et le mercure qui dépasse 40 degrés ne font pas bon ménage. Car en cas de fortes chaleurs, la longévité de votre batterie peut se voir légèrement modifiée, même s’il existe des technologies pour limiter la casse.
C’est que la chimie interne des packs et cellules peut être poussée dans ses retranchements si l’exposition est prolongée. Sachez en effet qu’au-delà des pertes de performances et d’autonomie, la capacité de recharge peut aussi se dégrader. Pour éviter le coup de chaud, voici le guide de survie de votre voiture électrique sous canicule.
Évitez de vous brancher en plein soleil
D’abord, premier conseil : évitez au maximum de recharger votre voiture électrique sous un soleil de plomb car vous exposez la batterie à un mini stress thermique en quelque sorte, provoquant une surchauffe inutile et le ralentissement du processus.

Par exemple, si vous faites le plein d’électricité sous une chaleur extrême, l’ordinateur de bord du véhicule et la borne ultra-rapide vont communiquer instantanément et activer une sécurité électronique, comme brider la puissance de charge, parfois jusqu’à la moitié de sa capacité habituelle. Par pure protection. Le temps d’attente peut alors jusqu’à doubler pour récupérer 80 % d’autonomie, transformant votre pause sur l’autoroute en un long moment.
Mais au-delà de ce point, ce geste peut accélérer en parallèle la dégradation. Le cumul de la chaleur ambiante et de celle générée par le flux électrique haute tension est, à long terme, irréversible sur la capacité maximale de votre batterie.

Pour maintenir les cellules à une température acceptable pendant l’effort de charge, le système de refroidissement liquide du véhicule est contraint de tourner à plein régime. Cette climatisation interne siphonne une telle quantité d’énergie qu’une partie des kilowattheures tout juste injectés est immédiatement consommée, amputant votre autonomie avant même de reprendre la route.
Rassurez-vous, la plupart des systèmes de refroidissement ou de gestion thermique des packs batteries sont très bien faits et parviennent à maintenir la température optimale pour pouvoir recharger sa voiture en plein cagnard. Donc c’est possible et pas du tout dangereux, d’autant plus que les bornes de recharge qui fonctionnent en extérieur résistent à des conditions climatiques ultra exigeantes.

Mais pour mettre toutes les chances de votre côté, privilégiez plutôt les sessions de recharge tôt le matin, tard en soirée, ou durant la nuit, lorsque la dalle de béton des stations n’accumule plus la chaleur. Ou bien, visez carrément les bornes de recharge abritées sous un toit ou implantées dans des parkings souterrains.
Opération ombre !
Donc votre premier geste pour protéger votre batterie est de fuir le soleil. Même pour stationner. Garer votre véhicule dans un garage, un parking couvert ou, a minima, sous un arbre, est le b.a.-ba.

À l’abri des rayons directs, la batterie redescend bien plus vite à une température de fonctionnement raisonnable après utilisation. Cela permettra également de diminuer le besoin de refroidir l’habitacle lorsque vous reprendrez la route.
L’astuce imparable ? Sortez vos pare-soleil et films réflecteurs : ils permettent de gratter jusqu’à 15 °C de moins dans l’habitacle.
Domptez le pré-conditionnement de la batterie
Ne sous-estimez pas la technologie de votre voiture électrique. Le pré-conditionnement permet de refroidir intelligemment la batterie avant de prendre la route ou de brancher le câble. Le but de cette action est de lui faire atteindre sa fenêtre de température idéale pour un rendement optimal.
Activez cette fonction via l’écran central ou votre application mobile, idéalement pendant que la voiture est encore branchée pour ne pas amputer votre autonomie.
Surveillez la pression de vos pneus
Avec le poids conséquent de leurs batteries, les véhicules électriques malmènent structurellement leurs pneus. Et bien sûr, le bitume brûlant est l’ennemi numéro un puisque la chaleur fait grimper la pression, altère la tenue de route et multiplie les risques de crevaison.
Alors n’hésitez pas à contrôler rigoureusement et régulièrement la pression (à froid) pour rouler en toute sécurité.
La climatisation avec modération
C’est votre allié le plus précieux en été, sachez qu’il est indispensable que votre système de climatisation soit parfaitement entretenu pour vous éviter de surconsommer. La base. Et oui, si vous allumez la clim, cela sollicite alors davantage la batterie et réduit légèrement votre rayon d’action, à moins de 10 km pour 100 km d’autonomie.
C’est peu, certes, et l’impact est bien inférieur à celui du chauffage en hiver, mais autant opter pour l’économie, non ? Alors votre alternative sur les trajets courts et à vitesse réduite sera d’ouvrir grand les fenêtres et laissez respirer la mécanique et vos finances !
Pensez à l’éco-conduite
Lors de périodes de canicule, votre conduite sera votre meilleure alliée. Alors oubliez tout ce qui provoque les pics d’intensité et font grimper la température interne des cellules de la batterie. Évitez donc les accélérations brutales et abusez du mode « éco », particulièrement sur autoroute, afin d’optimiser la gestion des flux d’énergie.

Rassurez-vous, vous pouvez rouler dans votre voiture électrique car non, les fortes chaleurs ne condamnent pas son usage. Les relevés d’usure des voitures électriques en circulation sont d’ailleurs unanimes : les batteries vieillissent très bien, peu importe les conditions d’utilisation.
En appliquant scrupuleusement ces quelques préceptes, vous protégerez donc au mieux votre véhicule à batterie contre la canicule et profiterez de vos trajets estivaux en toute sérénité.
Source : Voiture électrique et canicule : voici nos astuces pour préserver votre batterie et votre autonomie
Fuite de données JeVeuxAider : 550 000 profils de bénévoles piratés


Le vol de données informatiques continue de faire rage en France. Après l’ANTS, McDonald’s France, ou encore la DGFiP et la plupart des opérateurs télécom, c’est au tour d’un autre service de l’État de faire les frais d’une fuite de données.
C’est quoi JeVeuxAider ?
Cette fois ce sont plus de 550 000 comptes qui seraient concernés par ce piratage de la plateforme JeVeuxAider. Voici les données concernées :
- nom et prénom ;
- adresse e-mail ;
- numéro de téléphone ;
- adresse postale ;
- date de naissance ;
- informations liées au profil bénévole ;

La plateforme JeVeuxAider permet de connecter des associations ou plus généralement des organisations à but non lucratif avec des bénévoles volontaires. On y retrouve des organisations comme la SPA, Emmaüs, le Secours Catholique ou encore les Banques Alimentaires.
Le piratage semble avoir exclusivement touché les profils bénévoles et non les organisations.
À l’image du piratage qui a touché La France Insoumise en mai 2026, cette fuite pourrait permettre à des personnes malveillantes de constituer des listes associant des personnes et leurs convictions supposées. Elle pose un sérieux risque pour la vie privée des français concernés, en particulier à moins d’un an d’une élection présidentielle.
Les bons réflexes en cas de piratage
Si vous avez été victime d’un piratage ou d’une fuite de données, quelques bonnes pratiques sont à garder en tête pour mieux vous protéger. Frandroid en a fait une liste :
- Changer sans attendre les mots de passe des comptes concernés ;
- En profiter pour changer aussi les mots de passe identiques ou similaires sur d’autres services ;
- Utiliser des mots de passe uniques et solides (avec, pourquoi pas, un gestionnaire de mots de passe) ;
- Activer la double authentification (2FA) partout où c’est possible ;
- Activer les Passkeys quand c’est possible ;
- Dans les semaines à venir, se méfier des emails, SMS ou appels suspects, même s’ils semblent crédibles ;
- Ne jamais cliquer sur un lien ou télécharger une pièce jointe en cas de doute ;
- Prévenir ses contacts si le piratage peut les concerner ;
- Mettre à jour ses appareils et logiciels pour corriger d’éventuelles failles de sécurité ;
- En cas de virements frauduleux, faire un signalement sur la plateforme Perceval.
Source : Fuite de données JeVeuxAider : 550 000 profils de bénévoles piratés
Ce simulateur de vol secret de Google Earth est enfin disponible sans rien installer


En 2007, Google a glissé un simulateur de vol complet dans Google Earth sans prévenir personne. Pour le déverrouiller, il fallait connaître une combinaison secrète : Ctrl + Alt + A sous Windows, Command + Option + A sur Mac. Pas de menu, pas d’annonce. Un utilisateur est tombé dessus par hasard, l’astuce s’est propagée, et en 2008 Google a fini par l’officialiser avec son propre bouton dans le menu.
Le principe : deux avions, un F-16 et un Cirrus SR22 (un petit quadriplace à hélice), qui survolent les images satellites réelles de la planète entière. Sauf que pendant 18 ans, ce jouet est resté coincé dans la version à télécharger de Google Earth. La version navigateur, allégée, n’arrivait pas à le faire tourner. Le 12 juin 2026, Google a corrigé le tir : le simulateur est désormais disponible pour tout le monde, directement dans le navigateur, gratuitement.
Comment l’utiliser
C’est simple. Vous ouvrez Google Earth dans votre navigateur (Chrome, Safari, peu importe), vous cliquez sur « Explorer la Terre », puis sur le menu « Outils » en haut, et vous lancez le simulateur de vol. Concrètement, ça se pilote au clavier et à la souris, sans rien installer. Un détail qui compte : par défaut, Google affiche une carte abstraite sans relief. Pour profiter des vraies images satellites, Google précise qu’il faut basculer le fond de carte de « Plan » vers « Satellite ».
À noter aussi : la physique est simplifiée. Google le dit clairement, l’outil vise la balade au-dessus du globe, pas l’entraînement de pilote. Et si vous foncez trop vite ou que votre connexion rame, le terrain peut mettre un instant à se charger devant vous. Ce qui nous amène au seul truc vraiment impressionnant ici.
Pourquoi c’est plus malin qu’il n’y paraît
Un simulateur de vol, c’est la chose la plus dure qu’on puisse demander à une carte 3D. Déplacer la vue tranquillement, ça va : le logiciel a tout son temps pour charger le terrain qui arrive. Voler bas et vite, c’est l’inverse : le système doit récupérer, décompresser et afficher le monde plus vite que vous ne le traversez. Faire tourner ça dans un onglet de navigateur, c’est la preuve que la version web de Google Earth fait enfin le boulot qui nécessitait autrefois une application de bureau.
Google n’est pas le premier sur ce terrain. GeoFS, par exemple, propose depuis des années un simulateur de vol gratuit dans le navigateur, bâti sur le moteur Cesium et des images satellites mondiales. Mais avoir le constructeur de la carte qui ouvre la sienne en accès libre, ça change l’échelle. Le constructeur américain a d’ailleurs accompagné l’arrivée de profils d’altitude et de nouveaux formats d’import sur la version web, alignant peu à peu le navigateur sur les fonctions de l’édition professionnelle.
Bref, c’est gratuit, c’est sans installation, et c’est parfait pour aller crasher un F-16 sur le toit de votre maison en haute définition.
Source : Ce simulateur de vol secret de Google Earth est enfin disponible sans rien installer
Windows Defender suffit-il vraiment en 2026 ? La vérité sur les antivirus gratuits et payants
Faut-il payer pour un logiciel antivirus ou utiliser l’antivirus intégré à Windows ? Points clés à prendre en compte pour faire le bon choix
Vous venez d’acheter un nouvel ordinateur sous Windows. Ou vous avez récemment entendu parler d’une cyberattaque et vous vous demandez si votre protection est suffisante. Vous tapez dans Google : « est-ce que Windows Defender suffit ? » Et vous tombez sur deux camps radicalement opposés.
D’un côté, les articles qui vous disent que Windows Defender est parfaitement suffisant et que vous jetez votre argent par les fenêtres si vous payez pour un antivirus tiers. De l’autre, les sites de sécurité informatique souvent les mêmes qui vendent ou font la publicité de ces antivirus tiers qui vous expliquent en termes alarmistes que Defender n’est pas assez puissant.
La vérité, comme toujours, est plus nuancée. Et surtout, elle dépend entièrement de qui vous êtes et de ce que vous faites avec votre ordinateur.
Cet article va vous donner une réponse honnête, sans conflit d’intérêts, basée sur des données de tests indépendants et des critères concrets. À la fin, vous saurez exactement si vous avez besoin d’un antivirus payant ou pas.
Comprendre l’enjeu : pourquoi la sécurité informatique est plus critique que jamais
Avant de comparer les solutions, posons le contexte. Pourquoi se préoccuper de la sécurité de son ordinateur en 2026 ?
Windows : la cible numéro un des cybercriminels
Windows représente environ 72 % du marché mondial des systèmes d’exploitation pour ordinateurs de bureau. C’est de loin la plateforme la plus utilisée et donc la plus lucrative à attaquer pour les cybercriminels. La logique est simple : si vous voulez contaminer le plus d’ordinateurs possible avec le moins d’effort possible, vous vous concentrez sur Windows.
Ce n’est pas une question de qualité du système d’exploitation. C’est purement statistique. C’est la même raison pour laquelle les maladies se propagent plus vite dans les grandes villes, plus il y a de monde, plus le vecteur de propagation est efficace.
Les données que vous manipulez ont de la valeur
Vos photos de famille. Votre carnet d’adresses. Vos fichiers de travail. Vos accès bancaires enregistrés dans votre navigateur. Vos mots de passe. Vos conversations.
Chacun de ces éléments a une valeur sur le marché noir de la cybercriminalité. Les données personnelles se vendent, s’utilisent pour des arnaques ciblées, ou servent de levier pour des demandes de rançon. En 2026, la cybercriminalité génère plus de 10 000 milliards de dollars de dégâts annuels dans le monde davantage que le trafic de drogue mondial combiné.
Protéger votre ordinateur n’est plus une question de paranoïa. C’est une hygiène numérique de base.
Windows Defender / Microsoft Defender : qu’est-ce que c’est vraiment ?
Commençons par démystifier l’outil que Microsoft inclut dans chaque installation de Windows.
Un peu d’histoire pour comprendre où on en est
Windows Defender existe depuis Windows XP, mais pendant longtemps, c’était un outil limité qui ne combattait que les logiciels espions. Ce n’est qu’à partir de Windows 8 qu’il est devenu un véritable antivirus complet, et Microsoft a massivement investi dans son développement depuis.
En 2020, Microsoft a renommé une partie de l’écosystème en Microsoft Defender pour couvrir l’ensemble de la suite de sécurité qui inclut désormais bien plus qu’un simple antivirus. Le nom « Windows Defender Antivirus » reste utilisé pour désigner le composant antivirus spécifiquement.
Dans cet article, nous l’appellerons Defender par souci de simplicité.
Ce que Defender fait concrètement
Voici ce que Defender intègre nativement dans Windows 10 et 11 :
- Protection en temps réel : surveillance permanente des fichiers, des téléchargements, et des processus actifs.
- Protection basée sur le cloud : les échantillons suspects sont envoyés à Microsoft pour analyse rapide par ses serveurs.
- Pare-feu Windows : bloque les connexions réseau non autorisées.
- Contrôle des applications : bloque les programmes non reconnus ou non signés.
- Protection contre les rançongiciels : la fonctionnalité « Accès contrôlé aux dossiers » protège vos fichiers importants contre les ransomwares.
- Navigation sécurisée : intégration avec Microsoft Edge pour bloquer les sites malveillants.
- Analyse planifiée : scans automatiques périodiques en arrière-plan.
- Protection contre les exploits : mesures de durcissement contre les techniques d’exploitation de failles.
Et tout ça, gratuitement, déjà installé, sans rien faire.
Les performances de Defender : ce que disent les tests indépendants
Ne prenons pas la parole de Microsoft pour argent comptant. Regardons ce que disent les organismes de test indépendants, les seuls qui méritent vraiment d’être consultés pour ce type de comparaison.
AV-TEST et AV-Comparatives : les références mondiales
AV-TEST (Allemagne) et AV-Comparatives (Autriche) sont les deux laboratoires indépendants de référence mondiale pour tester les logiciels antivirus. Ils soumettent régulièrement des dizaines de solutions à des milliers de malwares réels, de menaces zero-day, et de tests de performance.
Ce ne sont pas des sites qui vendent de la publicité aux antivirus qu’ils testent. Ce sont des organismes certifiés et reconnus par l’industrie.
Les résultats pour Defender en 2025-2026
Les résultats sont globalement impressionnants pour un produit gratuit intégré :
| Critère | Defender (Windows 11) | Leaders du marché payants |
|---|---|---|
| Détection des malwares connus | 98 à 99,7 % | 99,5 à 100 % |
| Protection zero-day | Bonne (avec nuances) | Excellente |
| Impact sur les performances | Faible à modéré | Faible (Bitdefender, Avira) |
| Faux positifs | Légèrement supérieur à la moyenne | Variable |
| Score AV-TEST global | 18/18 (février 2026) | 18/18 pour les meilleurs |
Oui. Defender obtient un 18/18 dans les tests AV-TEST de février 2026. Le score maximum. C’est indiscutable et c’est une évolution remarquable par rapport à il y a cinq ou dix ans, où Defender était effectivement en retard sur les solutions tierces.
Mais ces chiffres appellent des nuances importantes.
Ce que les chiffres bruts ne disent pas
Le taux de détection à 98-99,7 % semble excellent. Mais 2 % d’échec, c’est combien de menaces ?
Sur les milliers de nouveaux malwares créés chaque jour, une protection à 98 % laisse passer potentiellement des dizaines de menaces nouvelles. Pour la grande majorité des utilisateurs, ce risque résiduel est gérable. Pour quelqu’un qui télécharge régulièrement des fichiers de sources peu fiables, c’est plus préoccupant.
Les menaces zero-day sont le vrai différenciateur. Les zero-days sont des malwares tellement récents qu’aucune base de données n’en a encore connaissance. C’est là que Defender montre ses limites : il s’appuie beaucoup sur la reconnaissance de signatures connues et sur la réputation des fichiers. Face à une menace absolument inédite, les solutions tierces qui utilisent de l’analyse comportementale avancée ont souvent une longueur d’avance.
Les faux positifs de Defender restent légèrement plus élevés. Cela signifie que Defender peut bloquer des programmes parfaitement légitimes en les identifiant à tort comme malveillants ce qui peut être frustrant, surtout pour les utilisateurs qui installent des logiciels moins connus.
Les avantages de Defender
Soyons fair. Voici ce que Defender fait vraiment bien.

C’est gratuit et c’est déjà installé
Pas de frais d’abonnement. Pas d’installation. Pas de décision à prendre. À partir du moment où vous utilisez Windows 10 ou 11, vous avez une protection de base fonctionnelle.

Intégration native = consommation minimale
Contrairement à un antivirus tiers qui tourne comme une application supplémentaire sur votre système, Defender est intégré dans le noyau de Windows lui-même. Il a accès aux couches les plus profondes du système d’exploitation, ce qui lui permet de fonctionner de façon plus efficiente en termes de ressources CPU et mémoire.
Un antivirus tiers, aussi léger soit-il, est une application supplémentaire qui s’exécute sur votre système. Sur un ordinateur récent et puissant, vous ne verrez pas de différence. Sur un PC plus ancien ou limité en RAM, la différence peut être perceptible.

Mises à jour via Windows Update
Les mises à jour de Defender passent par le même canal que les mises à jour de Windows? ce qui signifie qu’elles sont intégrées au processus que la plupart des utilisateurs ont déjà configuré en automatique. Pas de rappel supplémentaire, pas d’interface dédiée à gérer.

Pas de publicités, pas de tentation d’achat
Les antivirus gratuits des éditeurs tiers ont un modèle économique : vous montrer de la publicité et vous pousser à passer à la version payante. Bitdefender Free vous demandera régulièrement si vous voulez mettre à jour. Avast affiche des bannières. AVG fait de même.
Defender ne fait rien de tout ça. Il tourne silencieusement en arrière-plan sans jamais vous demander de l’argent.

Fonctionnalités souvent sous-estimées
Deux fonctionnalités de Defender méritent d’être mieux connues :
- L’Accès contrôlé aux dossiers : une protection anti-ransomware qui empêche toute application non autorisée de modifier vos dossiers sensibles (Documents, Images, Bureau…). Cette fonctionnalité est désactivée par défaut, pensez à l’activer dans les paramètres de Sécurité Windows.
- La protection contre les exploits : Defender intègre des mesures de durcissement contre les techniques d’exploitation de failles logicielles, équivalentes à certaines fonctionnalités premium d’antivirus tiers.
Les limites de Defender
Soyons tout aussi honnêtes sur ce que Defender ne fait pas.

Pas de VPN intégré
Les antivirus premium comme Norton, Bitdefender ou Kaspersky incluent un VPN, un réseau privé virtuel qui chiffre votre connexion Internet et masque votre adresse IP. Defender n’en propose pas. Si vous utilisez régulièrement des réseaux Wi-Fi publics (cafés, aéroports, hôtels), un VPN n’est pas un luxe.
Pas de gestionnaire de mots de passe
Les solutions tierces premium incluent souvent un gestionnaire de mots de passe intégré. Defender n’en propose pas, bien que Microsoft ait son propre gestionnaire de mots de passe dans Edge, qui reste séparé de l’antivirus.
Pas de protection bancaire renforcée
Bitdefender, Kaspersky et d’autres proposent un « mode coffre-fort » ou une navigation bancaire sécurisée, une interface isolée du reste du système pour les transactions financières, qui rend les keyloggers et les captures d’écran impossibles.
Pas de contrôle parental avancé
Si vous avez des enfants, les solutions tierces offrent des contrôles parentaux bien plus complets : filtrage de contenu par catégorie, limites de temps d’écran, rapports d’activité. Microsoft propose une solution séparée (Microsoft Family), mais elle n’est pas intégrée directement dans Defender.
Pas de support technique humain
Si vous avez un problème avec Defender, vous êtes seul avec la communauté Microsoft. Les antivirus tiers payants incluent généralement un support client accessible par chat, par téléphone, ou par email.
Des performances moins régulières sur les tests
Malgré son score de 18/18 en février 2026, Defender n’obtient pas systématiquement les meilleures notes à chaque cycle de tests. Certaines évaluations le placent légèrement en retrait sur la protection zero-day par rapport aux leaders comme Kaspersky ou Bitdefender.
Les antivirus tiers : gratuits et payants
Les options gratuites des éditeurs tiers
Si Defender vous semble insuffisant mais que vous ne voulez pas dépenser d’argent, plusieurs antivirus gratuits de qualité existent.
Bitdefender Antivirus Free : un des taux de faux positifs les plus faibles du marché, score 6/6 chez AV-TEST, extrêmement léger. Idéal si vous voulez « oublier » votre antivirus, il tourne en silence sans jamais vous déranger.
Avast Free Antivirus : taux de détection de 99,7 %, protection web intégrée, interface simple. Attention à la collecte de données, Avast a été épinglé pour avoir vendu les données de navigation de ses utilisateurs à des partenaires, même si ces pratiques ont été réformées depuis.
Malwarebytes Free : pas un antivirus complet (pas de protection en temps réel dans la version gratuite), mais un excellent outil de scan à la demande. Peut coexister avec Defender sans le désactiver, c’est la configuration recommandée pour une double vérification.
Les options payantes : ce que vous payez vraiment
Les antivirus payants se justifient principalement par leurs fonctionnalités supplémentaires, pas nécessairement par une protection radicalement supérieure.
| Solution | Prix annuel approximatif | Ce qui justifie le prix |
|---|---|---|
| Bitdefender Total Security | ~35-45 €/an | VPN, multi-appareils, contrôle parental, protection bancaire |
| Norton 360 | ~50-80 €/an | VPN illimité, Gestionnaire de mots de passe, 2 GB cloud backup, dark web monitoring |
| Kaspersky Premium | ~40-60 €/an | Excellente protection zero-day, VPN, Gestionnaire de mots de passe |
| ESET NOD32 | ~35-50 €/an | Légèreté exemplaire, idéal pour vieux PC, contrôle parental |
| AVIRA Prime | ~35-60 €/an | VPN illimité, multi-appareils, Gestionnaire de mots de passe, Outils d’optimisation |
| Avast Premium Security | ~35-60 €/an | Protection e-mail, sandbox, webcam shield |
À ce stade, Defender, Bitdefender Free et Avast Free offrent tous une protection comparable contre les menaces courantes. En plus d’une protection renforcée, vous payez pour les fonctionnalités périphériques : VPN, gestionnaire de mots de passe, protection bancaire, contrôle parental, et support technique.
Le tableau de décision : quel profil êtes-vous ?
Plutôt que de vous donner une réponse universelle qui n’existe pas, voici un tableau qui correspond aux différents profils d’utilisateurs.
| Profil | Recommandation | Pourquoi |
|---|---|---|
| Utilisateur basique : navigation web, emails, YouTube, réseaux sociaux | Defender suffit | Toutes les menaces courantes sont couvertes |
| Utilisateur prudent avec bonnes pratiques | Defender + Malwarebytes Free | Double vérification gratuite et légère |
| Téléchargeur fréquent (torrents, logiciels peu connus) | Antivirus tiers (Bitdefender, Kaspersky, Eset) | Meilleure détection comportementale des menaces inconnues |
| Utilisateur de Wi-Fi public régulier | Antivirus avec VPN inclus (Norton, Bitdefender, Kaspersky) | La protection réseau justifie l’abonnement |
| Famille avec enfants | Antivirus avec contrôle parental (Norton, Kaspersky) | Defender n’offre pas cette fonctionnalité nativement |
| Télétravailleur avec données sensibles | Antivirus payants | Protection bancaire, VPN, encryption |
| PC ancien / faible en RAM | Defender ou ESET NOD32 | Les plus légers sur les performances système |
| Petite entreprise / Auto-entrepreneur | Solution professionnelle (ESET, Kaspersky, Bitdefender for Business) | Gestion centralisée, support technique, conformité |
| Grande entreprise | Solution EDR dédiée (Crowdstrike, SentinelOne) | Defender ne suffit pas en environnement professionnel complexe |
Ce que Defender ne peut pas faire tout seul : les bonnes pratiques indispensables
Qu’importe l’antivirus que vous choisissez, il existe des comportements qui réduisent drastiquement votre risque d’infection et qu’aucun logiciel ne peut remplacer.

Maintenez Windows à jour
La majorité des cyberattaques exploitent des failles connues dans des logiciels qui n’ont pas été mis à jour. La mise à jour Windows que vous repoussez depuis trois semaines contient peut-être le correctif d’une faille activement exploitée en ce moment.
Utilisez des mots de passe uniques et un gestionnaire de mots de passe
Le vol de mots de passe est l’une des principales portes d’entrée des cybercriminels. Si vous utilisez le même mot de passe partout, une seule fuite de données sur n’importe quel site vous expose partout. Utilisez un gestionnaire de mots de passe, Bitwarden est gratuit et excellent.
Activez l’authentification à deux facteurs
Sur vos comptes importants (email, banque, réseaux sociaux), activez la double authentification. Même si quelqu’un récupère votre mot de passe, il ne pourra pas se connecter sans le deuxième facteur.
Méfiez-vous des pièces jointes et des liens
80 % des infections commencent par un e-mail de phishing ou un fichier téléchargé d’une source douteuse. Aucun antivirus ne peut vous protéger si vous cliquez consciemment sur un lien suspect ou ouvrez une pièce jointe d’un expéditeur inconnu.
Activez l’Accès contrôlé aux dossiers dans Defender
Cette fonctionnalité anti-ransomware est désactivée par défaut. Allez dans : Sécurité Windows → Protection contre les virus et menaces → Paramètres de protection contre les ransomwares → Accès contrôlé aux dossiers → Activer.
Utilisez-vous Windows Defender seul, un antivirus gratuit tiers, ou une solution payante ? Avez-vous déjà subi une infection malgré l’antivirus Windows Defender ou autre ? Pensez-vous que les antivirus payants valent encore leur prix en 2026, ou qu’ils surfent principalement sur la peur ?
Partagez votre expérience dans les commentaires.
Source : Windows Defender suffit-il vraiment en 2026 ? La vérité sur les antivirus gratuits et payants
Cette nouvelle arnaque Wero sur Facebook Marketplace fait des ravages
Une redoutable arnaque par SMS ciblant les utilisateurs du service de paiement Wero sévit actuellement sur la Marketplace de Facebook. Des escrocs, se faisant passer pour des acheteurs, envoient un lien frauduleux pour soi-disant finaliser une transaction. Ce lien mène en réalité à un site de phishing conçu pour dérober vos coordonnées bancaires. La vigilance est absolue : Wero ne demande jamais de cliquer sur un lien pour recevoir de l’argent.
{kind=link}
Vous mettez un objet en vente sur la Marketplace de Facebook, et un acheteur apparemment sérieux et pressé vous contacte. Il propose de régler immédiatement la somme via Wero pour « sécuriser la vente », avant même de récupérer le bien. La proposition semble honnête. Sauf que le SMS de confirmation qui suit est une porte d’entrée directe vers un enfer numérique. Une nouvelle campagne massive s’abat sur les vendeurs, exploitant la confiance naissante dans ce service de paiement européen pour siphonner leurs comptes.
Comment fonctionne exactement cette arnaque Wero ?
Le scénario est bien rodé. Une fois que vous acceptez la proposition de paiement, l’escroc vous demande simplement votre prénom et votre numéro de téléphone. Quelques instants plus tard, vous recevez un SMS. Le message, qui imite parfaitement une notification officielle, vous informe qu’un virement est en attente et vous invite à cliquer sur un lien pour « récupérer vos fonds ». C’est là que le piège se referme. Cette technique d’arnaque SMS est redoutable car elle joue sur l’instantanéité et l’appât du gain.

Ce lien ne mène évidemment pas à votre application bancaire, mais à un site miroir, une copie quasi parfaite de l’interface de Wero. En confiance, vous êtes invité à saisir vos informations personnelles et, surtout, vos coordonnées bancaires pour finaliser la transaction. Mais il n’y a pas d’argent à recevoir. Vous venez de livrer sur un plateau d’argent vos données les plus sensibles à des acteurs malveillants, qui peuvent alors les utiliser pour vider votre compte ou les revendre sur le dark web.
Pourquoi Wero est-il devenu une cible de choix pour les fraudeurs ?
Derrière le nom de Wero se cache une ambition européenne colossale. Lancé en 2024 sous l’impulsion de l’European Payments Initiative (un consortium de seize grandes banques européennes comme BNP Paribas ou BPCE), ce service vise à créer un champion du paiement souverain, capable de rivaliser avec les géants américains Visa, Mastercard, et surtout Apple Pay ou Google Pay. Le dispositif repose sur le réseau SEPA Instant, permettant des virements en moins de dix secondes avec un simple numéro de téléphone.
Cette montée en puissance, aussi impressionnante soit-elle, a un revers de médaille : elle attire les prédateurs. Avec des partenaires comme Orange, la SNCF ou Veepee, et un déploiement imminent chez les 13 millions de clients BPCE, la notoriété de Wero explose. Les fraudeurs exploitent cette popularité naissante et le fait que le grand public ne maîtrise pas encore parfaitement ses codes de sécurité. Pour eux, c’est une véritable aubaine, un terrain de jeu fertile où la méfiance n’est pas encore un réflexe.
Quels sont les réflexes à adopter pour ne pas tomber dans le panneau ?
La parade est simple, mais elle exige une vigilance absolue. Wero martèle un message sur son site officiel, une règle d’or à graver dans le marbre : le service n’envoie JAMAIS, sous aucun prétexte, de SMS ou d’e-mail contenant un lien pour recevoir un paiement. C’est le point fondamental. Si vous recevez un tel message, la seule action à entreprendre est de le supprimer. Ce type de phishing est conçu pour vous faire paniquer ou agir dans la précipitation.

Si le mal est fait et que vous avez cliqué et renseigné vos informations, n’ayez pas honte. Chaque seconde compte. Le premier réflexe est de contacter immédiatement votre banque pour faire opposition et sécuriser vos comptes. Ensuite, il est impératif de porter plainte auprès du commissariat de police ou de la brigade de gendarmerie la plus proche. Pour tordre le cou à ces pratiques, le service de paiement en ligne insiste sur la prévention : réfléchissez, ne cliquez pas, et au moindre doute, parlez-en à votre conseiller bancaire.
Foire Aux Questions (FAQ)
Wero peut-il m’envoyer un SMS pour confirmer la réception d’argent ?
Non, absolument jamais. Tout SMS ou e-mail vous demandant de cliquer sur un lien pour accepter un virement Wero est une tentative d’escroquerie. Le virement est automatique et ne nécessite aucune action de votre part.
Que faire si j’ai déjà communiqué mes informations bancaires sur le faux site ?
Contactez votre banque sans délai pour bloquer votre carte et surveiller toute transaction suspecte. Il est également crucial de déposer une plainte pour que les autorités puissent enquêter sur ces réseaux de fraudeurs.
Source: Cette nouvelle arnaque Wero sur Facebook Marketplace fait des ravages
Se préparer à l’expiration des certificats Windows Secure Boot – Le Monde Informatique
Plusieurs certificats concernant Secure Boot de Windows arrivent bientôt à échéance. Si pour la plupart les mises à jour se feront automatiquement, certains environnements nécessiteront des efforts supplémentaires. Tour d’horizon de ce qu’il faut savoir pour assurer une transition en douceur.
")
La vie des utilisateurs et des administrateurs de systèmes Windows s’apprête à être bouleversée. Microsoft compte en effet apporter une modification importante du mode de démarrage sécurisé (Secure Boot) de son système d’exploitation. Le problème est plus précisément lié aux certificats de Secure Boot : émis il y a 15 ans par la firme de Redmond ils arrivent à échéance et sont donc en cours de remplacement par d’autres plus récents. Mais pour continuer à bénéficier des protections de sécurité les plus récentes pour le processus de démarrage Windows, les utilisateurs comme les administrateurs IT doivent s’assurer que leurs systèmes Windows en sont bien équipés. Voici ce qu’il faut savoir pour assurer une transition sereine.
Qu’est-ce que Secure Boot ?
Il s’agit d’une fonction de sécurité qui vérifie, au démarrage de Windows, que tous les logiciels intégrés au micrologiciel sont signés par un certificat de confiance. En cas de non-correspondance, le logiciel est bloqué. Tout ce processus se déroule immédiatement au démarrage, avant même que l’OS ou tout autre élément ne se charge. Disponible sur les PC tournant sur un BIOS UEFI, cette fonction est apparue en 2011 pour assurer que seul un code signé et de confiance puisse s’exécuter lors du démarrage et éviter toute compromission initiale. D’abord disponible en option dans Windows 8 et 10, Secure Boot a ensuite intégré en standard Windows 11.
Que se passe-t-il avec les certificats Secure Boot ?
Pour faire face aux récentes menaces, Microsoft a émis en 2023 de nouveaux certificats Secure Boot pour remplacer ceux de 2011. Leur déploiement sur les terminaux Windows a commencé en 2024 et, selon l’éditeur, la quasi-totalité des PC et serveurs commercialisés à partir de 2025 intègrent déjà les certificats de 2023. Cependant, la plupart des systèmes plus anciens (fabriqués entre 2012 et 2024) sur lesquels Secure Boot est activé utilisent encore les certificats de 2011. Or ces derniers commenceront à expirer en juin.
Trois certificats Secure Boot de Windows arrivent à expiration cette année :
– KEK CA 2011 qui autorise les modifications apportées à la base de données Secure Boot et expirera le 27 juin 2026 ;
– UEFI CA 2011 qui signe les pilotes tiers pour permettre aux composants matériels de charger leur micrologiciel lors du démarrage, et expirera le 27 juin 2026 ;
– Windows Production PCA 2011 qui signe le chargeur d’amorçage Windows lui-même, le composant logiciel essentiel qui charge Windows depuis le lecteur vers la mémoire et expirera le 19 octobre 2026.
Pour les terminaux qui n’ont pas été livrés avec les certificats 2023 préinstallés, Microsoft déploie actuellement ces certificats via Windows Update.
Qu’advient-il des terminaux ne disposant pas des certificats mis à jour une fois que les anciens ont expiré ?
Sans ces derniers certificats, le PC continuera de fonctionner et recevra toujours les mises à jour Windows habituelles, mais plus celles de sécurité relatives au processus de démarrage. Les dernières protections pour le gestionnaire de démarrage Windows ne s’installeront donc pas et les mises à jour de la base de données Secure Boot ne s’appliqueront pas. Les listes de révocation bloquant les malwares connus ne seront pas non plus actualisées. Le système sera alors pratiquement sans défense face aux menaces au niveau du démarrage. À long terme, l’absence des certificats actuels peut également entraîner des problèmes de compatibilité avec les prochains systèmes d’exploitation, micrologiciels, matériels ou logiciels dépendant de Secure Boot.
Comment les certificats Secure Boot sont-ils mis à jour ?
Pour la plupart des terminaux dont les mises à jour Windows sont gérées par Microsoft (notamment grand public mais aussi certains pour les entreprises et l’enseignement), les certificats récents seront installés automatiquement via Windows Update dans le cadre du processus d’actualisation mensuelle habituel, sans qu’aucune intervention supplémentaire ne soit nécessaire. L’éditeur déploie progressivement ces certificats depuis juin 2025 ; il est donc possible que votre système en dispose déjà.
Mais certains terminaux peuvent nécessiter une mise à jour du micrologiciel fournie par le fabricant avant que le système puisse appliquer les derniers certificats Secure Boot. En effet, ils doivent être enregistrés dans les bases de données UEFI de la carte mère, auxquelles Secure Boot fait appel lors du processus de démarrage. HP, Dell, Lenovo et d’autres grands fabricants de PC ont publié des évolutions du BIOS spécialement conçues pour garantir que leurs systèmes puissent accepter correctement ces certificats. Microsoft recommande à ses clients de consulter les pages d’assistance de leur fabricant d’équipement d’origine (OEM) pour vérifier si des mises à jour du micrologiciel sont disponibles et de les installer si nécessaire. L’éditeur tient aussi à jour une liste des pages d’assistance des OEM concernant la préparation aux mises à jour de Secure Boot.
Les systèmes managés par des entreprises peuvent suivre différents processus de mise à jour et nécessitent généralement l’intervention d’un administrateur informatique. Microsoft propose un mini-site complet intitulé « Mises à jour des certificats Secure Boot : conseils à l’intention des professionnels de l’informatique et des entreprises », qui traite notamment de la vérification de l’état de Secure Boot, de la préparation, des considérations relatives au micrologiciel, des options de déploiement (y compris automatisé), de la surveillance et de la correction, ainsi que du dépannage.
Quels PC et serveurs recevront automatiquement les certificats mis à jour ?
Seuls les équipements fonctionnant sous des versions de Windows actuellement prises en charge par Microsoft recevront les certificats Secure Boot mis à jour via Windows Update :
– Windows 11 24H2, 25H2 et 26H1 (toutes les éditions) ; les éditions Entreprise et Education de Windows 11 23H2 ; et les éditions 2024 de Windows 11 Long-Term Servicing Channel (LTSC) ;
– Windows 10 22H2 inscrits au programme Extended Security Updates (ESU) et toutes les éditions de Windows 10 Long-Term Servicing Branch (LTSB) /LTSC 2016, 2019 et 2021 jusqu’à leurs dates de fin de prise en charge LTSC ;
– Windows Server 2019, 2022 et 2025 : couverts par des instructions distinctes dans le guide Secure Boot Playbook pour Windows Server.
Comment savoir si les derniers certificats Secure Boot ont été installés ?
Les particuliers et les utilisateurs professionnels ou du secteur de l’éducation bénéficiant de mises à jour gérées par Microsoft peuvent vérifier dans Sécurité Windows > Sécurité de l’appareil > Secure Boot. Des icônes et des messages d’état indiquent si votre appareil est entièrement à jour et si des mesures doivent être prises. Pour plus de détails, consultez la page d’assistance de Microsoft intitulée « État de la mise à jour des certificats Secure Boot dans l’application Sécurité Windows. »
Que savoir d’autre concernant les mises à jour des certificats Secure Boot ?
Le Secure Boot étant intégré au firmware, certains environnements peuvent nécessiter des étapes supplémentaires. Cela peut concerner des configurations matérielles spécialisées, certains systèmes virtualisés dans lesquels le fournisseur de la plateforme gère le comportement du micrologiciel, ou encore des terminaux qui dépendent de l’assistance du fabricant. Microsoft travaille en étroite collaboration avec ses partenaires matériels et de PC pour garantir une large compatibilité et une transition en douceur. Avec le Patch Tuesday de mai 2026 et les prochaines mises à jour mensuelles, certains terminaux pourraient nécessiter un redémarrage supplémentaire pendant l’installation. Il s’agit d’un redémarrage unique, prévu et documenté, permettant d’appliquer le dernier gestionnaire de démarrage une fois les certificats enregistrés dans le micrologiciel.
Quelles ressources sont disponibles pour vous aider à déployer et à résoudre les problèmes liés aux nouveaux certificats Secure Boot ?
– aka.ms/getsecureboot : une ressource de référence que Microsoft tient à jour avec toutes les informations et recommandations concernant les mises à jour des certificats Secure Boot ;
– Terminaux Windows pour les particuliers, les entreprises et les établissements scolaires avec mises à jour gérées par Microsoft : comprend une section de dépannage pour les problèmes liés à la récupération BitLocker ou à un système qui ne démarre pas après l’installation des nouveaux certificats ;
– Guides pratiques Secure Boot pour les clients Windows et les serveurs Windows : ils accompagnent les administrateurs informatiques tout au long du processus de planification et de déploiement dans des environnements automanagés ;
– Guide de dépannage Secure Boot destiné aux administrateurs système ;
– Rapport d’état Secure Boot dans Windows Autopatch qui sert à surveiller à l’échelle du parc informatique, sans frais supplémentaires.
Source: Se préparer à l’expiration des certificats Windows Secure Boot – Le Monde Informatique
Fin du Vision Pro : Apple dissoudrait l’équipe de son casque de réalité mixte
Après des années de développement et un lancement en grande pompe à un tarif prohibitif, il semblerait que le Vision Pro d’Apple soit sur la sellette avec la dissolution de l’équipe responsable du casque.
C’était supposé être « the next big thing » pour Apple, cela s’est révélé être un des rares ratés de la firme. Le Vision Pro, l’ambitieux casque de réalité virtuelle et augmentée, aurait tant de mal à se vendre qu’Apple serait doucement en train d’abandonner ses ambitions sur le secteur et de passer à autre chose.
D’après des informations obtenues par MacRumors, la pomme aurait mis fin à ses efforts de recherche et développement sur le produit et dispatché les ingénieurs responsables du projet au sein d’autres équipes. Un abandon qui ressemble pas mal à un adieu définitif.
Une fin prévisible
Les chiffres de vente de l’appareil ne semblent jamais avoir été au rendez-vous des espérances d’Apple. Quelques mois après sa sortie, le gadget se serait vendu à moins de 100 000 exemplaires. Fin 2024, la firme plafonnait à 600 000 unités et la sortie d’une nouvelle version avec puce M5 n’aurait rien arrangé, puisque seuls 45 000 exemplaires auraient été écoulés au cours du dernier trimestre 2025.
Pire encore, d’après une source interne qui s’est livrée à MacRumors, le taux de retours et de remboursement de l’appareil aurait été plus élevé que celui de tout autre appareil Apple sur le marché. Une tendance déjà discernable dans les premières semaines de sa commercialisation. Il faut dire qu’à quasiment 4000 € l’appareil, les acheteurs et acheteuses étaient en droit de s’attendre à une expérience ultra haut de gamme, ce que le casque peinait à offrir en raison de son écosystème logiciel maigrichon.
Les lunettes comme alternatives
L’arrivée d’un second modèle moins onéreux semble donc sérieusement compromise, comme l’évoquaient déjà des rumeurs fin 2025. Il semblerait qu’Apple préfère se concentrer sur ses lunettes connectées qui pourraient s’inspirer, à terme, des progrès technologiques développés pour le Vision Pro.
VisionOS devrait continuer à être mis à jour et rien ne dit qu’un futur casque ne sortira pas à l’occasion d’un futur progrès technologique quelconque, mais, pour le moment, les priorités semblent avoir évolué chez Apple avec une bonne partie de l’équipe dédiée au Vision Pro partie en renfort sur le projet Siri 2.0.
Source: Fin du Vision Pro
Canicule et voiture électrique : quel impact sur la batterie ?
Une vague de chaleur précoce s’abat sur la France en cette seconde quinzaine de mai 2026, avec des modèles saisonniers qui pointent un mois plus chaud de 1 à 3 °C par rapport aux normales. Et avec des étés qui se durcissent années après année, la question revient à chaque fois : nos voitures électriques tiennent-elles le coup ? On va donc tenter de voir si elles sont sensibles à la chaleur, et on va vous donner quelques conseils pour que votre véhicule s’en sorte au mieux durant cette période difficile.
En voiture, la chaleur est inconfortable et la température dans l’habitacle peut facilement dépasser les 50 degrés. Certaines surfaces exposées et zones de préhension peuvent même parfois dépasser les 80 degrés. Dans cette fournaise, nous avons tous le même reflex : mettre la climatisation à fond. La plupart des modèles récents bénéficient même d’un accès rapide avec une fonction « refroidir l’habitacle » pour vite faire tomber la température. Les voitures électriques sont, pour la majorité, connectées et la climatisation peut être gérée à distance grâce aux applications.
Le mieux est de laisser les vitres entrouvertes les premières minutes de roulage et lorsque la climatisation est activée afin de chasser l’air chaud à l’extérieur. Mais, nous allons le voir, les fortes chaleurs ont aussi un impact sur d’autres éléments que l’habitacle, particulièrement pour les voitures électriques.
Quels risques sur la batterie ?
Les batteries lithium-ion doivent rester dans une fourchette de température propre à chaque modèle pour garantir un bon fonctionnement et leur durabilité, généralement entre 20 et 25 degrés Celsius. Au-delà de 30 °C, certaines études — comme celle du site américain Recurrent Auto — pointent une perte d’autonomie qui peut grimper jusqu’à 30 % sur les modèles les moins bien armés. Les batteries chauffent aussi rapidement lorsqu’elles sont chargées à forte puissance et qu’un trajet à vitesse élevée est effectué. D’où l’importance d’un système de refroidissement performant pour ne pas constater une perte de puissance, aussi bien du moteur électrique que celle de recharge.
Bonne nouvelle : en 2026, l’immense majorité des voitures électriques vendues neuves bénéficie d’un refroidissement liquide. Les Tesla, Hyundai, Kia, BYD, Audi, Porsche, Renault, Peugeot, Volkswagen et autres ne souffrent pas vraiment de problèmes de chaleur, hormis peut-être lors d’une utilisation vraiment intensive, comme sur circuit par exemple. Lors de fortes chaleurs, il n’y a pas de risque significatif de perte de puissance ou de détérioration des cellules.
Pour quelques modèles plus anciens encore présents sur le marché de l’occasion, comme la Renault Zoé, la Nissan Leaf de première génération ou la Volkswagen e-UP, la température de la batterie est régulée au moyen d’une ventilation forcée. Un système moins coûteux qu’un refroidissement liquide, mais beaucoup moins efficace. Certains utilisateurs ont vu le fonctionnement de leur voiture temporairement altéré lorsque la température de la batterie dépasse les 45 °C. Cela se traduit par une perte de puissance à l’accélération, ou encore une batterie qui ne se recharge pas aussi vite que prévu. Dans le pire des cas, cela peut même dégrader les cellules si la température élevée est maintenue sur de longues périodes, sur cinq ans, on parle de 20 à 30 % de perte d’autonomie supplémentaire par rapport à un modèle refroidi par circuit liquide.

Atteignez l’autonomie énergétique
Pour utiliser l’énergie solaire quand vous en avez vraiment besoin, faites confiance à Anker Solix et ses solutions de stockage plug-and-play qui misent sur l’intelligence.
Dans la plupart des cas, la voiture fera en sorte, d’elle-même, de réguler la puissance (en charge ou en roulant) au niveau de la batterie afin d’éviter toute détérioration de celle-ci. Vous pouvez donc utiliser votre voiture normalement, mais ne soyez pas étonné si vous constatez une baisse de puissance lors d’une recharge rapide en plein soleil sur une voiture qui n’est pas refroidie par un système liquide.
La recharge sur bornes publiques peut-elle être affectée ?
Exposées en général directement aux rayons du soleil, les bornes de recharge sont remplies de composants électroniques. Même s’ils sont bien isolés de l’extérieur la plupart du temps, la température de fonctionnement pour une borne de recharge oscille entre -25 et +45 degrés selon les données techniques fournies par les fabricants.
Un seuil qui est parfois atteint, voire dépassé, en cas de fortes chaleurs. La puissance de recharge peut ainsi être altérée. Plusieurs membres de notre rédaction ont pu rencontrer ce cas. Notamment chez Tesla sur les anciens Superchargeurs V2 où la borne se mettait en sécurité, à 60 kW, au bout de quelques minutes de charge. Poser un linge humide sur le connecteur permettait de retrouver la puissance maximale. Un problème quasi inexistant sur les V3, et inexistant sur les V4 (jusqu’à 500 kW) que Tesla déploie depuis 2025 en Europe, avec une électronique de puissance beaucoup plus efficiente et un refroidissement repensé. Mais le problème n’a pas disparu pour autant : nous avons aussi rencontré le cas sur différents réseaux « locaux », avec des bornes rapides en courant continu DC en plein soleil, incapables de dépasser quelques kW de puissance, quand elles ne se mettaient pas tout simplement en défaut. Le système de gestion électronique peut déclencher une mesure de sécurité pour éviter une surchauffe sur la borne. Ainsi, l’opération de recharge sera interrompue avant son terme.
Idéalement, pour éviter ce genre de phénomènes, il faudrait que les bornes de recharge soient protégées des intempéries, comme cela se fait dans certaines stations, avec un toit protégeant de la pluie et du soleil. La réglementation européenne AFIR impose désormais des stations de recharge rapide d’au moins 150 kW tous les 60 km le long des grands axes, avec un objectif de 400 kW de puissance totale par station fin 2025 et 600 kW fin 2027 : autant d’occasions de repenser ces infrastructures avec de meilleurs abris.
Quel impact sur l’autonomie ?
Si le froid a un impact réel sur l’autonomie des voitures électriques, les fortes chaleurs n’ont pas le même impact en France. En tout cas, c’est ce que nous avons constaté durant nos nombreux essais de voitures électriques menés depuis plusieurs années maintenant, et par tous les temps. Tant que vous restez sous la barre des 30 °C, la batterie travaille dans une plage confortable et l’autonomie ne bouge quasiment pas.
En réalité, si les températures sont élevées, vous utiliserez la climatisation. Et, effectivement, cela aura un impact sur l’autonomie puisque le système puise l’électricité de la batterie pour fonctionner. Les voitures électriques possèdent néanmoins un avantage : la grande majorité des modèles récents est équipée d’une pompe à chaleur réversible particulièrement économe.
Contrairement aux véhicules thermiques, nul besoin de « laisser tourner le moteur » et de consommer une quantité importante d’énergie pour générer de l’air froid. Précisons toutefois que les voitures électriques qui ne sont pas équipées d’une pompe à chaleur pour le chauffage (et qui comptent donc sur une résistance pour chauffer l’habitacle en hiver, comme sur les thermiques) disposent malgré tout d’un circuit de climatisation classique pour produire du froid. Une climatisation consomme environ 1 kW par heure de fonctionnement, contre à peu près le triple pour le chauffage d’un véhicule doté d’une résistance électrique.
Pour économiser quelques précieux kilomètres d’autonomie, n’hésitez pas à activer le recyclage de l’air. En règle générale, une climatisation fonctionne à une puissance de 1 à 2 kW et fait perdre entre 15 et 25 km d’autonomie à une voiture, en fonction du modèle. À comparer au chauffage en hiver, qui peut monter à 3, voire 4 kW dans le cas d’une résistance. Avec la présence d’une pompe à chaleur, on revient sur des valeurs proches de la climatisation, certains systèmes les plus efficaces descendant même à 500 W.
Quand Tesla prend les devants
En 2020, la Californie a été touchée par de très fortes chaleurs. Tesla avait alors prévenu ses clients qu’il était préférable de ne pas recharger leur voiture à certaines heures en raison de la canicule et des limitations énergétiques locales.
Un problème amené à se multiplier avec les vagues de chaleur successives toujours plus intenses, comme on l’a vu sur l’été 2025 où l’ensemble du continent a multiplié les épisodes caniculaires.
Pas d’inquiétudes à avoir en France
En France, pour le moment, Tesla n’a pas encore eu besoin d’envoyer un message de ce genre à ses clients puisque le réseau électrique français reste plus fiable et robuste que son homologue américain. La climatisation, elle, gagne du terrain : environ 25 % des résidences principales sont désormais équipées selon les dernières données ADEME, contre une part bien plus faible il y a quelques années, un changement qui pèse sur le réseau l’été.
Le pic de consommation sur le réseau français reste hivernal, avec un record absolu de 91 228 MW atteint le 6 janvier 2026 à 10h30, selon les données éco2mix de RTE. Mais l’écart se resserre : le 30 juin 2025, la consommation a touché 57 GW à 13h, soit 13 % de plus qu’à la même date l’année précédente, et le pic estival a frôlé les 60 GW lors de la première canicule. Le record estival historique tient toujours, à 59,1 GW le 25 juillet 2019.
Il faut aussi nuancer : en cas de fortes chaleurs sur tout le territoire, certaines centrales nucléaires (celles refroidies en circuit ouvert sur un cours d’eau) peuvent être contraintes de ralentir leurs réacteurs si la température du cours d’eau devient trop élevée. C’est exactement ce qui s’est passé l’été dernier : EDF a dû arrêter le réacteur 1 de Golfech alors que la Garonne approchait les 28 °C, le seuil réglementaire de température de rejet. Un précédent qui dit ce que l’été 2026 risque de répéter.
Pour résumer, si les fortes chaleurs peuvent avoir un impact sur les véhicules électriques et l’infrastructure de recharge, cela dépend principalement de la voiture et de la borne utilisée. Au quotidien, vous ne devriez pas ressentir de différences majeures lors de l’utilisation de votre auto électrique, mais dans le cas où vous prévoyez un long trajet avec des recharges sur des bornes rapides régionales, prévoyez un peu plus large niveau autonomie pour être paré à une borne hors service ou très lente.
Source: Canicule et voiture électrique : quel impact sur la batterie ?