💻 Assistance, dépannage Informatique, Val de Reuil, Les Damps, le Vaudreuil, Louviers et ses alentours
TechInfo s'occupe des problèmes informatiques, de la conception de sites internet et d'applications ainsi que de la formation sur Val de Reuil, le Vaudreuil, Lery Pose, Louviers et ses alentours. Arrêtez de jeter, faites réparer !
Aujourd’hui, il est presque impossible d’acheter un ordinateur qui ne soit pas équipé d’un disque dur SSD. Bien plus rapides que leurs homologues HDD (disques durs), ils atteignent désormais des capacités largement suffisantes pour les usages courants. Au point que les HDD tombent en désuétude.
Ces derniers sont pourtant encore utiles, notamment pour le stockage de masse. Parce qu’ils peuvent contenir plus de données, et aussi parce qu’ils sont moins chers que leurs petits frères.
En coulisses, Western Digital travaille à les rendre bien plus performants qu’actuellement. La marque présente deux nouvelles technologies susceptibles de réduire l’écart entre HDD et SSD.
Comment Western Digital veut redorer le blason des disques durs HDD
La première innovation s’appelle « High Bandwidth Drive ». Elle consiste à utiliser des têtes de lecture et d’écriture distinctes sur chaque plateau, ce qui permet des opérations de lecture/écriture simultanées. Résultat : le disque dur est plus rapide dans les deux cas.
La deuxième idée est intitulée « dual pivot ». Comme son nom l’indique, le principe est d’ajouter un pivot séparé pour encore plus de lectures et écritures en même temps.
Un disque dur à « double pivot » // Source : Overclock3D
Les premiers prototypes affichent une vitesse deux fois supérieure, sachant que Western Digital vise le x8. Cela donnerait du 2 Go par seconde, en sachant que la consommation énergétique n’augmenterait pas.
En revanche, les interfaces SATA actuelles ne peuvent pas gérer une telle vitesse. Cela obligera donc à les modifier pour une prise en charge du plein potentiel de ces nouveaux HDD
Si suivre sa consommation d’électricité est monnaie courante en domotique, suivre la consommation d’eau est souvent plus complexe, mais c’est toutefois un poste qui fait fuiter pas mal de monnaie. Alors il serait temps de s’y mettre, mais simplement. Le suivi électrique est primordial avec la domotique, il est tout aussi intéressant et nécessaire de suivre la consommation d’eau du foyer. Au-delà des questions de gaspillage, le tarif de l’eau ne cesse de grimper lui aussi et utiliser la puissance et l’intelligence de la domotique pour suivre aussi la consommation d’eau est nécessaire.
Oui mais voilà, pour suivre de manière efficace sa consommation d’eau, il faut intervenir sur l’arrivée d’eau. Un emplacement stratégique de la maison où, sauf quand on est du métier, il devient compliqué d’intervenir dans le risque de condamner la maison en eau et devoir faire appel à un professionnel. Au vu des risques et de la complexité de l’intervention, beaucoup font l’impasse sur ce suivi.
L’optimisation de la consommation d’eau est devenue une priorité, tant pour la planète que pour le portefeuille. Si les compteurs communicants se généralisent, rares sont les solutions permettant de suivre sa consommation d’eau sans couper les tuyaux.
Mais la donne change avec un objet connecté très très intelligent et pratique qui permet de suivre très efficacement et précisément la consommation d’eau à l’arrivée générale sans intervention technique et donc sans risque de tout casser.
Le Water Grip de Quandify se présente sous la forme d’un boîtier compact et robuste. Contrairement aux compteurs divisionnaires classiques, il n’y a pas de turbine interne, pas de chiffres qui tournent, pas de raccord, de joints… En bref, il n’a vraiment rien d’un compteur. C’est pourtant bel et bien le cas et il va tout changer.
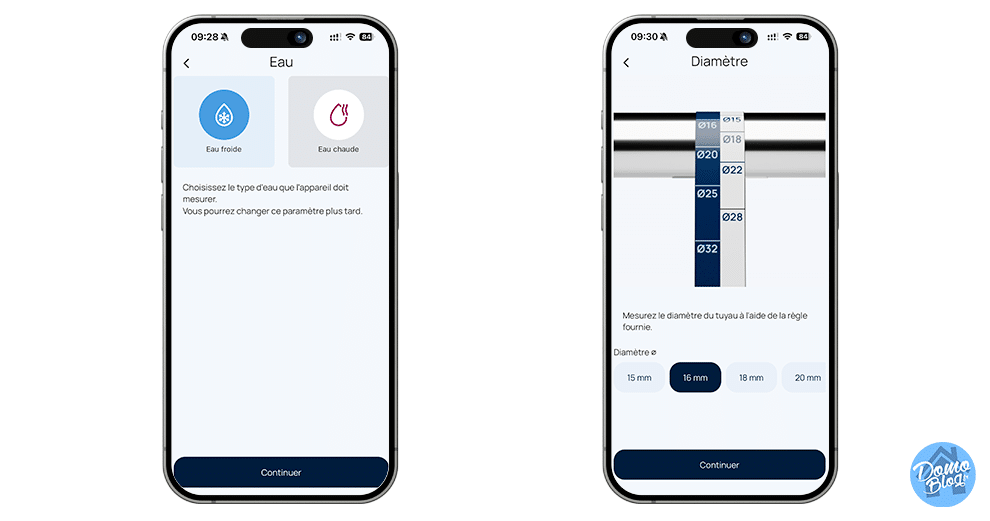
Tout réside dans son mode de fonctionnement révolutionnaire qui permet à tout un chacun de suivre très précisément sa consommation d’eau sans aucune intervention sur le réseau. Discret, le Water Grip est conçu pour s’adapter aux tuyaux standards de tous types et de tous diamètres. Cuivre, PER, multicouche… il est compatible avec la plupart des installations en eau domestique.
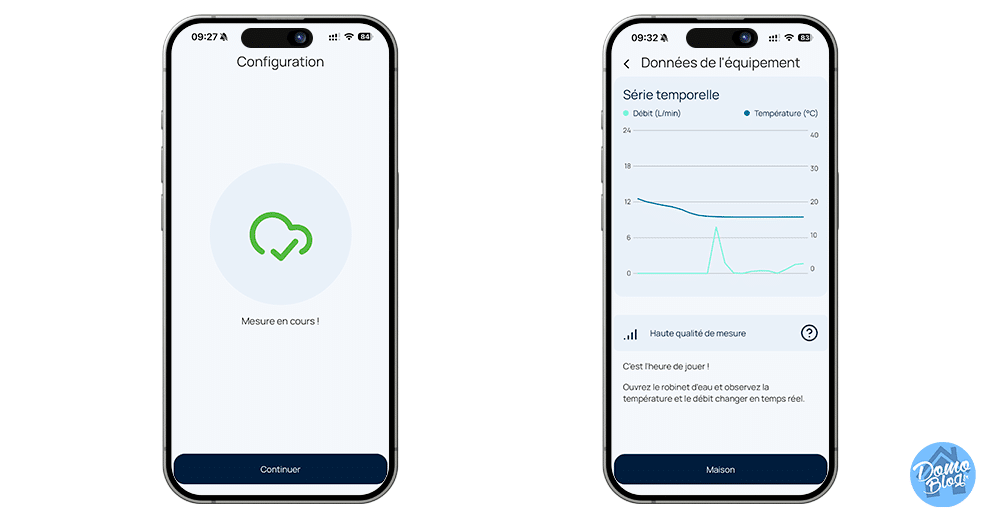
Une installation en un clin d’oeil sans besoin du sourire du plombier
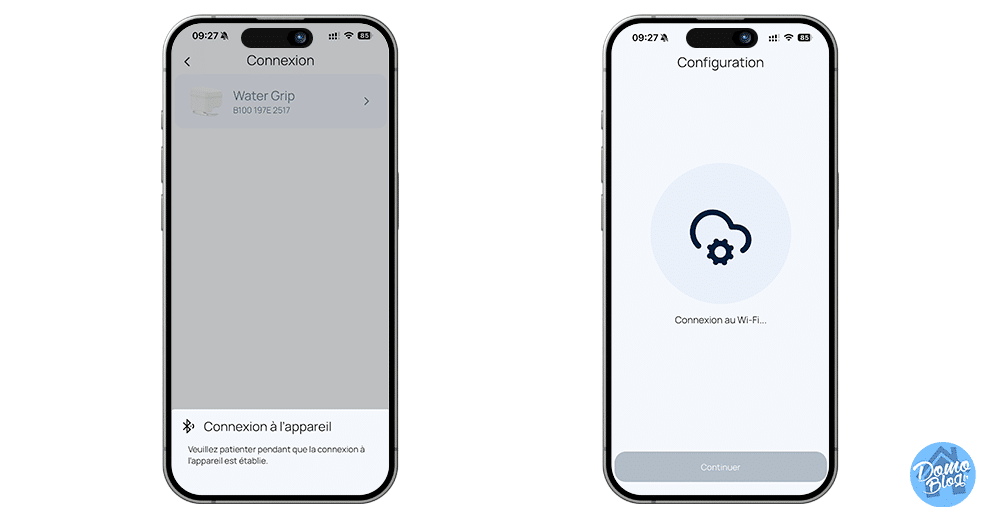
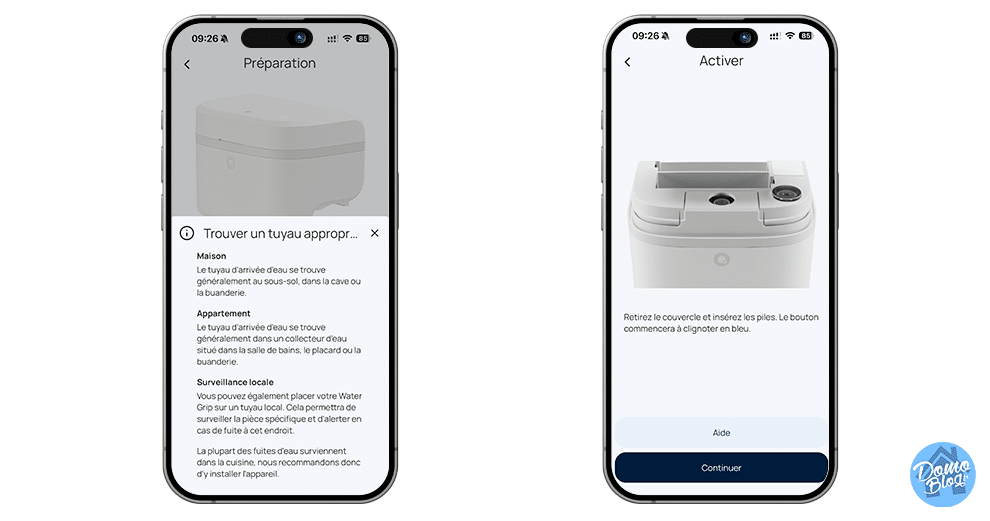
L’installation du compteur, c’est le plus gros point fort de ce produit. Le Water Grip utilise la technologie ultrasonique non intrusive. Pour faire simple pas besoin de découper les tuyaux pour intercaler le compteur et permettre à une turbine de comptabiliser les Litres d’eau consommés. Il se fixe sur votre tuyau et utilise la technologie ultrasons pour détecter les fuites et les variations de débit et vous avertir en cas de détection de fuite avant même que les dégâts ne surviennent.
L’installation est alors on ne peu plus simple, en moins de 2 minutes chrono le compteur est en place et compte déjà les litres d’eau qui s’écoulent dans le tuyau.
Clipser : On place le capteur autour du tuyau.
Serrer : Le mécanisme assure un contact optimal pour les capteurs.
Connecter : L’appairage se fait via l’application dédiée (iOS/Android).
En moins de 2 minutes, l’appareil commence à lire les vibrations et le flux à travers la paroi du tuyau. Aucun risque de fuite lié à l’installation puisqu’on ne touche pas à l’étanchéité du réseau.
Développé en étroite collaboration avec l’un des plus grands groupes d’assurance suédois, Länsförsäkringar, afin de garantir qu’il offre tout ce dont vous pourriez avoir besoin pour protéger votre maison contre les dégâts d’eau coûteux.
Fonctionnalités et Précision
Le Quandify Water Grip ne se contente pas de lire des chiffres, il analyse votre usage avec une excellente precision sur la mesure du débit standard (+/- 2 à 5%) et une très haute sensibilité sur l’analyse de très faible débit d’eau (détection de fuites).
Application mobile pour le suivi depuis smartphone
L’application mobile est simple, il y a tout ce qu’il faut pour suivre sa conso en quelques ecrans.
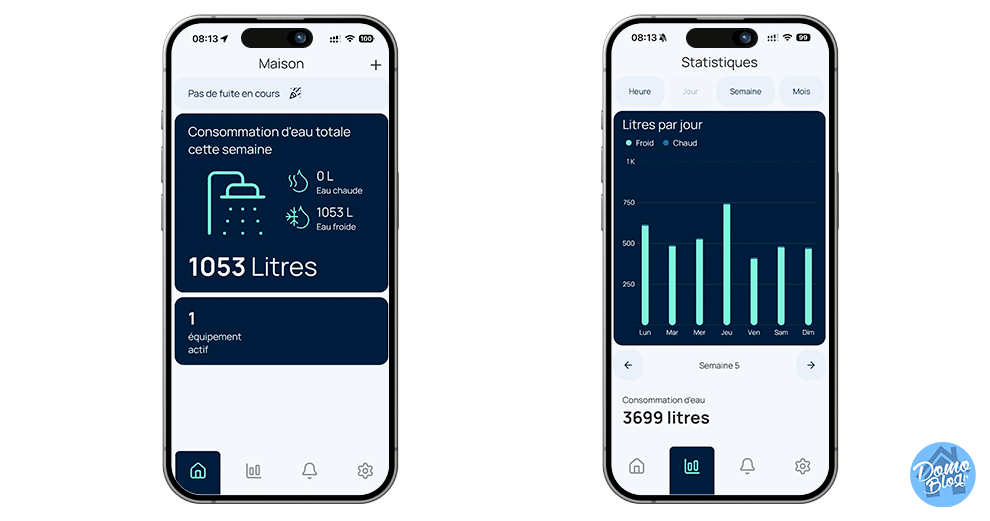
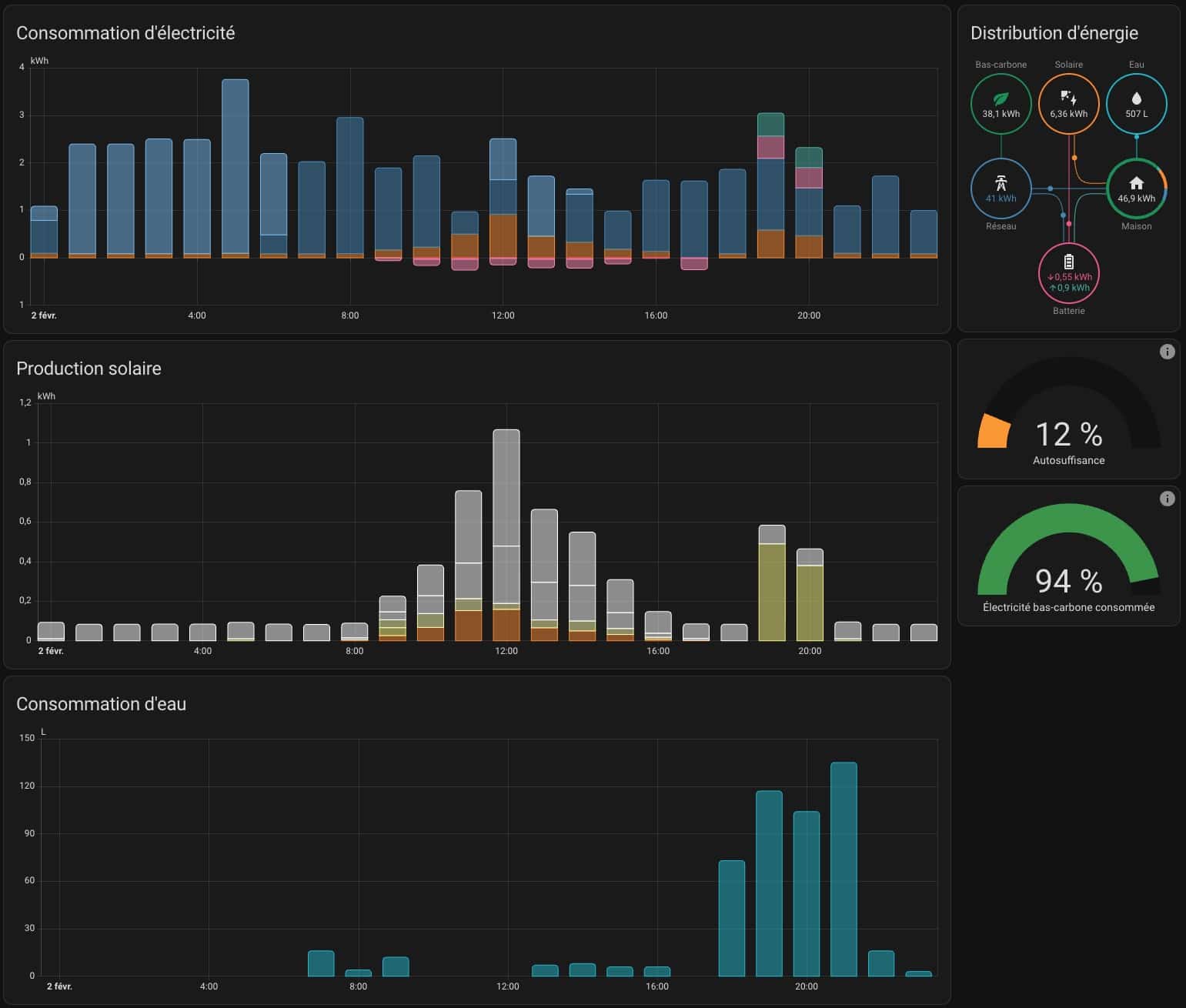
Vous pouvez revenir sur des périodes données en appliquant des filtres sur les périodes de votre choix et visualiser précisément votre consommation d’eau.
Suivi en temps réel
Grâce à sa connectivité Wi-Fi, vous suivez votre consommation au litre près. L’interface graphique est intuitive et permet de distinguer les pics de consommation (douches, lave-linge, arrosage). La connectivité nécessite l’utilisation du cloud pour suivre les données, c’est sans doute le seul inconvénient majeur.
Si ce compteur est intéressant pour sa simplicité de mise en œuvre par n’importe qui sur n’importe quelle installation, c’est aussi un compteur qui dispose d’un support dans Home Assistant. On peut alors donner une autre dimension au compteur et l’intégrer dans le tableau de bord énergie de la domotique en deux cliques. Cela passe par l’installation d’une intégration disponible dans HACS et l’utilisation du compteur créé sur l’application mobile pour relever les données dans le cloud et en disposer sur Home Assistant.
Une fois fait et après quelques jours, vous verrez un suivi très précis de votre consommation en eau en plus de la consommation électrique du foyer.
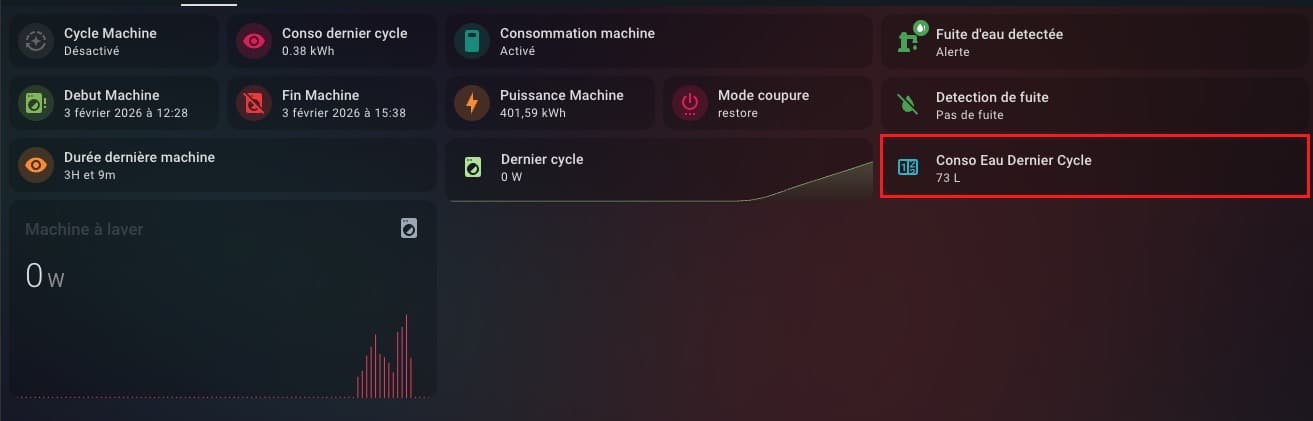
Enfin, avec un peu de YAML et une rapide automatisation, je peux intégrer à mon suivi de la machine à laver, un suivi de la consommation sur chaque cycle en plus du reste.
C’est la fonctionnalité qui sauve. Le système est capable de détecter des micro-fuites (goutte-à-goutte) ou des anomalies de débit prolongées, envoyant une notification immédiate sur votre smartphone.
Faut-il craquer pour le Water Grip ?
Le Quandify Water Grip est une petite révolution pour la gestion de l’eau. Il s’adresse à ceux qui veulent un contrôle total sans les contraintes techniques de la plomberie traditionnelle. Il a selon moi deux points négatifs qui n’entâchent en rien son efficacité, mais qui sont importants de signaler : La dépendance au cloud pour disposer du suivi dans la domotique et son tarif élevé. C’est un investissement intelligent pour les propriétaires bailleurs, les gestionnaires de parcs immobiliers ou les particuliers soucieux de leur empreinte écologique.
Le Monde a révélé cette semaine l’échec du projet XPN. Ce logiciel devait faciliter le travail des forces de l’ordre, mais c’est l’inverse qui s’est produit, avec un préjudice estimé à 257,4 millions d’euros par la Cour des comptes. Explications.
Le développement d’un nouveau logiciel de rédaction des procédures pénales a été lancé il y a une décennie. Photo Sipa/Christine Biau
« Gabegie hors norme », « naufrage administratif », « incroyable gaspillage d’argent public », « fiasco »… Les termes utilisés par la presse et par les syndicats de police pour qualifier le projet XPN sont sévères. C’est aussi le cas d’un document de la Cour des comptes, daté du 16 octobre dernier et dévoilé par Le Mondecette semaine.
Cette ordonnance de 500 pages, rédigée par la magistrate en charge de l’instruction à la chambre du contentieux, revient sur l’échec d’XPN, un programme informatique qui devait faciliter le travail des policiers. Développé depuis une décennie, l’outil est toujours inutilisable, à cause de nombreux dysfonctionnements. Il aurait déjà coûté 257 millions d’euros, selon la Cour des comptes. On vous explique comment c’est arrivé.
Des chicaneries « de niveau cour d’école »
Reprenons depuis le début. Lorsqu’elles rédigent un acte lors d’une enquête (procès-verbal, auditions, perquisitions, saisies, interpellations, garde à vue, etc.) pour le transmettre à la justice, les forces de l’ordre utilisent un logiciel de rédaction des procédures pénales. Aujourd’hui, la police nationale passe en « grande partie » par le Logiciel de rédaction de procédures de la police nationale (LRPPN).
Mais, comme les services de l’État le soulignent dans un récent projet d’achat public, LRPPN est devenu « un outil à la technologie obsolète », inadéquat pour « prendre le virage numérique ». Son remplacement par un logiciel plus moderne est envisagé dès 2014, relate Le Monde. Le développement du nouveau programme est lancé dès l’année suivante.
Au départ, le projet est envisagé comme un outil commun à la police et à la gendarmerie, qui dispose de son logiciel maison. Le service de technologie et des systèmes d’information de la sécurité intérieure est chargé de mener une première réflexion. Une commissaire de police y est nommée en tant de cheffe de projet en mars 2016, malgré son inexpérience en la matière. Elle est épaulée par la société Capgemini.
Mais très vite, les choses se gâtent : des tensions apparaissent et la gendarmerie se désengage. Un acteur du projet, cité par la Cour des comptes, évoque de chicaneries « de niveau cour d’école », relève Le Monde. La direction générale de la police nationale (DGPN) assure désormais seule la maîtrise d’ouvrage.
Un outil pas adapté aux réalités du métier
Le projet, dénommé d’abord LRP4, est d’emblée critiqué – au point qu’une consultation est organisée par l’administration en 2017 pour lui trouver un nouveau nom, indique Le Monde. Objectif : faire participer et voter les policiers pour favoriser « l’acceptation » du programme informatique. C’est le terme Scribe (pas le plus populaire) qui est retenu.
Ce qui ne suffira pas à sauver le projet. Pannes fréquentes, pertes de temps, manque d’ergonomie… En plus d’être trop tourné vers la production de statistiques, l’outil en cours de développement est jugé inadapté aux besoins des enquêteurs. À titre d’exemple, il faut « 17 clics pour intégrer un PDF » sur le logiciel et il est « impossible d’intégrer des fichiers supérieurs à 5Mo sans dégrader leur qualité », note la Cour des comptes. Quand des photos excèdent cette taille, elles « deviennent alors inexploitables par les magistrats ».
À ces dysfonctionnements techniques s’ajoutent des problèmes organisationnels. La Cour des comptes décrit un projet « au contenu mal défini » et une « gouvernance éclatée ayant conduit à la dilution des responsabilités ». Le Monde pointe des lourdeurs bureaucratiques, avec de trop nombreux comités aux réunions sporadiques.
Six personnes mises en cause
Après des années de développement, Scribe est un échec. Le programme change encore de nom en 2022 pour se relancer et devient XPN. Trois ans plus tard, il est toujours inutilisable, selon nos confrères. Dans son ordonnance, la Cour des comptes mentionne « des irrégularités comptables significatives » et conclut à une « faute grave » ayant causé un « préjudice financier significatif ». Coûts de développement, des missions d’appui, de la perte de temps des enquêteurs… La douloureuse s’élève à 257,4 millions d’euros.
Six personnes – dont deux anciens directeurs de la police et deux anciens secrétaires généraux du ministère de l’Intérieur – peuvent être tenues responsables de ce gros raté, selon les Sages. Charge désormais à la chambre du contentieux de se prononcer sur l’existence d’infractions (à savoir « violation des règles de contrôle budgétaire » et « défaut d’organisation et de surveillance »), voire de prononcer des sanctions. XPN est-il définitivement enterré ? Son déploiement n’est pas prévu avant le troisième trimestre 2028. Un calendrier « ambitieux » selon la Cour des comptes.
La fin de l’ADSL attendra. Orange reporte la fermeture commerciale de son réseau cuivre au 31 janvier 2027 pour 8 000 communes, en raison de la lenteur du déploiement de la fibre optique.
Le calendrier prévoyait qu’à la fin du mois de janvier 2026, l’ADSL ne serait plus disponible pour des millions de Français. C’était sans compter sur les aléas du déploiement de la fibre optique. Orange vient de revoir sa copie en catastrophe, en repoussant d’une année entière la fermeture commerciale de son réseau cuivre pour plus de la moitié du pays. Un aveu d’impuissance face à un chantier, colossal, qui accumule les retards.
Le calendrier de fermeture du réseau cuivre vole en éclats
Après avoir martelé pendant des mois que la transition vers la fibre se déroulerait comme prévu, Orange a publié mi-décembre un fichier Excel fleuve de 13 542 pages. Dans ce dernier, comme l’a remarqué Le Monde, on découvre une liste des 8 000 communes où la fermeture commerciale du cuivre glisse au 31 janvier 2027 au lieu de 2026.
Ces territoires représentent près de 23 millions d’habitations et d’entreprises, soit la moitié des locaux français. Autant dire que le report n’a rien d’anecdotique. D’ailleurs, 41 communes supplémentaires, qui totalisent 173 000 habitations, verront même leur extinction définitive du réseau décalée jusqu’en janvier 2028. Le planning initial est en train de partir en fumée.
Nicolas Guérin, le secrétaire général d’Orange, défend cette décision par la volonté de ne « prendre aucun risque en matière de déconnexion d’abonnés ». L’ARCEP, le régulateur des télécoms, avait d’ailleurs clairement posé les règles en janvier 2025, en faisant comprendre qu’il n’était pas question de fermer le cuivre sans un déploiement fibre complet. L’opérateur assure s’être « plié strictement aux recommandations » du régulateur, même si cela implique de mettre un coup de frein aujourd’hui.
Un réseau cuivre qui coûte encore 500 millions d’euros par an à Orange
Les chiffres officiels sont pourtant très flatteurs. 94% des habitations françaises peuvent désormais s’abonner à la fibre. Mais ce sont les 6% restants qui posent problème. Ces 3 millions de locaux encore non raccordés représentent justement les cas les plus complexes à traiter, avec dans le lot des maisons isolées, des hameaux perdus, et des zones rurales difficiles d’accès. Bref, les raccordements les plus coûteux et techniques.
Le plan national Très haut débit, lancé en grande pompe en 2013, devait boucler la couverture intégrale fin 2025. Raté. Les derniers kilomètres de fibre à tirer s’avèrent être les plus ardus. Pour Orange, ce retard a un coût, estimé à 500 millions d’euros par an rien que pour maintenir en vie un réseau cuivre qui date des années 1960.
Malgré ce contretemps majeur, le processus continue d’avancer. Dans trois semaines, le 27 janvier, 960 000 nouveaux logements perdront définitivement accès à l’ADSL. Ils rejoindront les 253 000 qui ont déjà opéré la bascule. D’ici 2030, tout le territoire devrait avoir dit adieu au cuivre. Du moins en théorie, si les délais ne dérapent pas davantage entre-temps.
Amazon, fournisseur officiel de mauvaises idées en matière de vie privée depuis 1870 vient de nous pondre une nouvelle trouvaille !! À partir du 25 mars, si quelqu’un vous achète un cadeau via votre liste de souhaits Amazon, le vendeur tiers récupère votre adresse de livraison. Oui, votre VRAIE adresse !! Après en tant que français on a l’habitude que tous les escrocs de la planète aient nos infos persos . Mais rassurez-vous, Amazon a trouvé une solution ! Est-ce qu’il s’agit de corriger le problème ? Que nenni !! Ils nous recommandent simplement d’utiliser une boîte postale. Sympa !
Parce que jusqu’ici, quand un pote vous envoyait un truc depuis votre wishlist, le vendeur tiers voyait votre ville et votre région… c’est déjà pas top, mais bon. Sauf que maintenant, c’est l’adresse COMPLÈTE qui part chez le vendeur. Numéro, rue, code postal, la totale…
Et vous vous en doutez, ça touche en premier lieu les créateurs de contenu, les streamers, et tous les crevards qui ont une wishlist publique pour que leur communauté puisse leur offrir des trucs net d’impôts ^^.
Donc suffit qu’un harceleur crée un faux compte vendeur sur Amazon Marketplace (La vérification d’identité ? Minimale !), met un article à 3 euros, attend qu’un fan l’achète via la wishlist de sa cible… et hop, il a l’adresse complète récupérée. Pas besoin d’être un génie. Ou alors suffit d’attendre que le vendeur tiers laisse fuiter le fichier Excel dans lequel il stocke ses commandes… La vie est toujours pleine de surprises quand il s’agit de leaker des données perso.
EDIT : Merci à Matthieu qui m’a envoyé la preuve ! Amazon.fr vient d’envoyer un email à ses utilisateurs pour confirmer que ce changement arrive bien en France à compter du 25 mars 2026. L’option permettant de restreindre les achats auprès de vendeurs tiers pour les articles de vos listes sera supprimée. Donc c’est plus une hypothèse, c’est confirmé… faites le ménage dans vos wishlists MAINTENANT.
Et côté RGPD ?
En Europe, le RGPD impose que le partage de données personnelles repose sur une base légale. Consentement explicite, intérêt légitime, ou exécution d’un contrat et pas une case pré-cochée planquée dans les CGU.
Le problème, c’est qu’Amazon change les règles du jeu en cours de route, sans demander un consentement spécifique pour ce nouveau partage d’adresse avec des tiers. Et bien sûr, le moment venu, la CNIL pourrait avoir deux mots à dire là-dessus… après, on sait comment ça se passe, les amendes mettent des années à tomber. D’ailleurs, Amazon s’est déjà pris 746 millions d’euros par le Luxembourg en 2021 pour non-respect du RGPD mais visiblement, ça ne les a pas trop calmés.
Comment protéger votre adresse ?
Maintenant concrètement, voici ce que vous pouvez faire (ça ne marche pas à 100% mais c’est mieux que rien) :
Allez dans votre compte Amazon, section « Listes » puis « Gérer la liste ». Vérifiez que votre wishlist est bien en mode « Privée » si vous ne voulez pas que n’importe qui la voie. Attention, le réglage par défaut c’est « Publique »… donc si vous n’avez jamais touché à ça, c’est probablement ouvert aux quatre vents.
Et si vous VOULEZ la garder publique (streamers, créateurs), utilisez une adresse qui n’est pas votre domicile. En France, une boîte postale La Poste coûte ~50 euros par an. Y’a aussi les Amazon Locker ou les points Mondial Relay… ce qui revient quand même à dire « débrouillez-vous », j’en ai bien conscience.
Le vrai problème
Le fond du problème, vous l’aurez compris, n’est pas technique. C’est qu’Amazon traite l’adresse de livraison comme une donnée de transaction banale alors que c’est une info sensible. Mais non, une adresse postale c’est pas un numéro de commande. Et surtout ça casse tout le principe d’anonymat des wishlists surtout quand la plateforme encourage les wishlists publiques depuis des années.
Bref, c’est confirmé pour la France au 25 mars, alors prenez les devants et prévenez votre influenceur préféré de faire le switch.
On en parlait depuis le MWC 2024 comme d’une curiosité technologique réservée aux opérateurs. Aujourd’hui, le kit FTTR de Huawei débarque sur Amazon. Pour un peu plus de 200 euros, vous pouvez désormais tirer de la fibre invisible dans chaque pièce de votre maison sans sortir la perceuse.
Source : Frandroid
Le FTTR, ou Fiber-To-The-Room, n’est plus un concept de salon tech ou une exclusivité pour les abonnés de Zeop à La Réunion. Huawei liste son kit complet sur Amazon en Europe.
Plutôt que de galérer avec des répéteurs Wi-Fi qui perdent 50 % de débit au premier mur porteur, ou de tirer de l’Ethernet dans les murs, ici vous tirez de la fibre partout. Littéralement. Huawei propose désormais son modem-routeur, ses points d’accès secondaires et surtout sa fibre optique adhésive en vente libre.
Le tout sans avoir besoin de connaissances d’ingénieur réseau ou de défoncer vos cloisons pour passer du câble Ethernet catégorie 7. C’est une alternative sérieuse et enfin concrète aux systèmes Mesh haut de gamme qui coûtent souvent un bras pour un résultat parfois aléatoire.
L’Optixstar F50 : on fait les présentations
Le cœur du système, c’est l’Optixstar F50. Ce modem-routeur coûte 86 euros. À cela, il faut ajouter un point d’accès « Sub-FTTR » à environ 62 euros pour chaque pièce supplémentaire, un répartiteur à 25 euros et le fameux câble fibre. Huawei vend 10 mètres de fibre monomode transparente pour 27 euros.
ONT/routeur FTTR Huawei V166a‑20
Au total, pour équiper un appartement avec un point d’accès secondaire, la facture grimpe à 200 euros environ. C’est le prix d’un bon système Wi-Fi 6/7 Mesh, mais avec une stabilité physique incomparable. Techniquement, le F50 supporte jusqu’à 256 appareils en simultané. Il propose des ports 2,5GE et même du 10GE côté utilisateur.
Le système iFTTR F50 permet de déployer jusqu’à 16 « sub FTTR » (satellites) en fibre dans les pièces : l’idée est d’avoir du Wi‑Fi très haut débit, avec un marketing à « 2000 Mbps Wi‑Fi everywhere ».
Source : Frandroid
Il y a cependant un bémol. La version vendue actuellement sur Amazon se contente du Wi-Fi 6 (802.11ax). C’est un peu frustrant en 2026, mais la version Wi-Fi 7 existe.
Source : Frandroid
Le vrai point fort, c’est cette fibre transparente de 1,2 mm. Elle est enrobée d’un adhésif qui se fixe sur vos plinthes ou vos murs avec un petit outil dédié. C’est presque invisible. Huawei annonce une latence de transfert en itinérance (roaming) inférieure à 10 ms. En clair, vous passez du salon à la chambre pendant un appel visio ou une partie de cloud gaming sans la moindre coupure.
Pourquoi c’est peut-être le futur du réseau domestique
Le problème du Wi-Fi, même avec les dernières normes, reste la physique. Les ondes radio détestent le béton et les interférences des voisins. La solution idéale a toujours été le câble Ethernet, mais personne n’a envie de voir des câbles RJ45 courir le long des murs du salon ou de percer des trous partout, surtout quand on est locataire.
La fibre optique FTTR résout cette équation. C’est « future proof » car le support physique (la fibre) peut encaisser des évolutions de débit massives sans avoir à être remplacé. On parle déjà de passer à 10 Gb/s dans chaque pièce.
Alors, faut-il craquer ? Pour la plupart des gens, c’est du délire. Mais si vous avez une grande maison, des murs épais et que votre Wi-Fi vous rend fou, l’option est tentante. En France métropolitaine, les opérateurs historiques observent encore la technologie. Mais voir le matériel disponible à l’unité change la donne : vous n’avez plus besoin d’attendre le bon vouloir d’Orange ou de Free pour moderniser votre installation.
La DGFiP a annoncé le 18 février que les IBAN d’environ 1,2 million de contribuables ont pu être consultés suite à un piratage du fichier national des comptes bancaires. Cette fuite de données comporte bien un risque: les escrocs peuvent tenter une fraude au prélèvement bancaire. Voici comment s’en prémunir.
Une fuite de données bancaires d’une ampleur inédite et qui pourrait vous coûter cher. À moins que vous ne preniez certaines précautions. Ce mercredi 18 février, la Direction générale des finances publiques (DGFiP) a annoncé avoir découvert que les informations de 1,2 million de comptes bancaires avaient pu être consultées illégitimement.
La faute à un acteur malveillant qui a usurpé les identifiants d’un fonctionnaire du fisc. Il a ainsi pu accéder et consulter une partie du fichier national des comptes bancaires (Ficoba). Il s’agit d’un fichier recensant l’ensemble des comptes bancaires ouverts dans les établissements bancaires français, soit 300 millions au total.
D’après la DGFiP, ce pirate n’aurait pu consulter « que » 0,4% de ce fichier. Malgré tout vous pourriez faire partie des victimes. Si c’est le cas, vos coordonnées bancaires (RIB et IBAN), mais aussi votre identité, votre adresse postale ainsi date et lieu de naissance et dans certains cas identifiant fiscal auraient pu être consultés.
• Un risque bien réel de prélèvement frauduleux
La DGFiP ce mercredi s’est voulue plutôt rassurante en soulignant que la consultation du Ficoba « ne permet pas de consulter les soldes des comptes bancaires, a fortiori de faire des opérations ». Le pirate n’a donc pas pu récupérer par exemple vos informations de carte bleue, et ne pourra pas effectuer de transactions directement sans votre consentement.
Néanmoins ce jeudi 19 février, au lendemain de l’annonce de ce piratage, la Fédération bancaire française (FBF) s’est montrée plus alarmiste. Dans un communiqué, elle a souligné que les informations récupérées « pourraient être utilisées pour des mandats frauduleux ».
La FBF explique qu’à partir d’un IBAN, de faux créanciers peuvent demander l’exécution de prélèvements facilement. Et ainsi souscrire des abonnements et des services qui seraient payés par le prélèvement sur cet IBAN obtenu illégalement. L’escroc pourrait aussi par exemple acheter sur Amazon avec vos sous puisque sur ce site il est possible de payer via prélèvement SEPA.
Dans une autre mesure, cette fuite de données vous expose également à un risque d’arnaque au faux conseiller bancaire. Un escroc pourrait vous contacter et se faire passer pour un agent de votre banque pour vous dérober des informations encore plus précieuses que celles qu’il a déjà. Sa démarche pourrait être rendue crédible par le fait qu’il connaisse votre identité, votre adresse, votre IBAN…
• Comment savoir si je suis concerné?
À l’heure actuelle, on ne sait pas qui sont les 1,2 million de comptes bancaires qui ont été consultés. Les victimes seront contactées par la DGFiP ou leur(s) établissement(s) bancaire(s), qui leur annonceront que leurs informations FICOBA ont été divulguées.
Surveillez donc vos mails ainsi que votre espace de banque à distance via le site ou l’application mobile de votre banque pour voir si vous n’avez pas reçu une alerte. En revanche, n’attendez pas de savoir si vous êtes concerné ou non pour être vigilant.
• Plusieurs précautions à prendre
Dans son communiqué, la FBF invite d’abord tous les clients bancaires à consulter régulièrement leur compte pour détecter tout incident ou anomalie. » Connectez-vous au moins 1 fois par semaine à votre espace de banque à distance et vérifiez les opérations inscrites à votre compte », conseille-t-elle.
Mais surtout, pour vous prémunir du risque de prélèvement frauduleux, mettez en place une liste blanche des créanciers autorisés. Plusieurs banques proposent effectivement de mettre en place une telle liste blanche pour filtrer les prélèvements. Toute tentative de prélèvement d’un mandataire qui n’est pas dans cette liste sera rejetée.
Pour mettre en place une protection de ce type, il faut généralement contacter votre banque afin de lui donner une liste de créanciers autorisés.
• Et si j’ai déjà été prélevé?
Sachez que vous pouvez également mettre en place une liste noire. Pour ce faire il faut également contacter votre conseiller bancaire, mais cela demande d’avoir déjà identifié un créancier frauduleux. Cela suppose donc que vous auriez été victime.
Soyez aux aguets: si vous recevez une notification de votre banque vous disant qu’un mandataire que vous ne connaissez pas souhaite mettre en place un virement, refusez cette demande. Et mettez tout de suite ce compte étranger sur votre liste noire.
Et si jamais vous constatez que ce compte vous a déjà prélevé de l’argent, alors vous pouvez tout de même agir. Contactez votre banque dans les 13 mois suivant cette opération frauduleuse et signalez-lui. Vous êtes effectivement protégé par le Code monétaire et financier en cas de prélèvement frauduleux ou d’opération pour laquelle vous n’avez jamais signé de mandat.
Depuis deux ans, les assistants de codage dopés à l’intelligence artificielle sont devenus des compagnons quasi permanents pour de nombreux développeurs. Complétion de code, génération de fonctions, refactoring automatique, explication de bases de code héritées : la promesse était simple et séduisante – coder plus vite, avec moins d’erreurs, et se concentrer sur la logique métier plutôt que sur la syntaxe. Pourtant, une question commence à s’imposer dans les équipes techniques : et si ces outils devenaient moins bons à mesure qu’ils se généralisent ?
Jamie Twiss (un spécialiste des données qui travaille à l’intersection de la science des données, de l’intelligence artificielle et du crédit à la consommation) a mis le doigt sur un malaise croissant dans la communauté : une étude empirique et retour terrain parmi d’autres qui suggèrent que la qualité réelle des assistants de codage IA stagne, voire se dégrade, malgré des modèles toujours plus gros et plus coûteux à entraîner.
Sur le papier, chaque nouvelle génération de modèles promet de meilleures capacités de raisonnement, une compréhension plus fine du contexte et une réduction des erreurs. Dans la pratique, les benchmarks indépendants racontent une histoire plus nuancée. Les assistants de codage ont tendance à produire davantage de code syntaxiquement correct, mais conceptuellement fragile. Les solutions proposées passent les tests simples, mais échouent dès que la complexité augmente ou que le contexte métier devient implicite.
Ce décalage est particulièrement visible dans les tâches de maintenance et de refactoring. Là où un développeur expérimenté identifie des dépendances cachées, des effets de bord ou des conventions d’architecture, l’assistant IA se contente souvent d’une transformation superficielle. Le résultat compile, mais introduit une dette technique supplémentaire, parfois difficile à détecter immédiatement.
Quand la génération de code favorise la médiocrité statistique
Le cœur du problème réside dans la nature même des modèles de langage. Ils ne comprennent pas réellement le code : ils prédisent des séquences probables à partir de vastes corpus existants. Or, une grande partie du code public disponible est de qualité moyenne, redondant, ou mal documenté. En s’entraînant massivement sur ces sources, les assistants tendent à reproduire des patterns médiocres, voire obsolètes.
Avec l’adoption massive de ces outils, un cercle vicieux se met en place. Le code généré par IA est de plus en plus publié, indexé, puis réutilisé comme donnée d’entraînement. Autrement dit, les modèles commencent à apprendre à partir de leur propre production, ce qui amplifie les approximations, les anti-patterns et les erreurs subtiles. Ce phénomène de « pollution du corpus » inquiète de plus en plus les chercheurs.
Une illusion de productivité qui masque des coûts cachés
À court terme, l’usage d’un assistant IA donne une impression de gain de productivité indéniable. Les tickets sont fermés plus vite, les lignes de code s’accumulent, et les délais semblent mieux tenus. Mais plusieurs équipes rapportent un effet retard : le temps gagné à l’écriture est souvent perdu plus tard en revue de code, en débogage ou en correction d’incidents en production.
Le problème est accentué chez les développeurs juniors. Exposés en permanence à des suggestions plausibles mais parfois erronées, ils risquent de perdre des occasions clés d’apprentissage. L’IA devient alors une béquille cognitive, réduisant la capacité à raisonner sur des algorithmes, à comprendre la complexité ou à anticiper les cas limites.
Le retour d’expérience du PDG de Carrington Labs
Ci-dessous un extrait de sa tribune :
Dans le cadre de mes fonctions de PDG de Carrington Labs, fournisseur de modèles de risque d’analyse prédictive pour les établissements de crédit, j’utilise fréquemment du code généré par LLM. Mon équipe dispose d’un environnement de test où nous créons, déployons et exécutons du code généré par l’IA de manière entièrement automatisée. Nous l’utilisons pour extraire des caractéristiques pertinentes pour la construction de modèles, selon une approche de sélection naturelle du développement de caractéristiques. Cela me confère un point de vue unique pour évaluer les performances des assistants de programmation.
Un cas de test simple
J’ai constaté ce problème de manière empirique ces derniers mois, mais récemment, j’ai effectué un test simple mais systématique pour déterminer s’il s’aggravait réellement. J’ai écrit un script Python qui chargeait un dataframe puis recherchait une colonne inexistante.
df = pd.read_csv(‘data.csv’)
df['new_column'] = df['index_value'] + 1 #there is no column ‘index_value’
Évidemment, ce code ne s’exécuterait jamais correctement. Python génère un message d’erreur clair indiquant que la colonne «*index_value*» est introuvable. Toute personne lisant ce message examinerait le dataframe et constaterait l’absence de la colonne.
J’ai envoyé ce message d’erreur à neuf versions différentes de ChatGPT, principalement des variantes de GPT-4 et la plus récente GPT-5. J’ai demandé à chacune d’elles de corriger l’erreur, en précisant que je souhaitais uniquement le code complet, sans commentaire.
C’est évidemment une tâche impossible*: le problème réside dans les données manquantes, et non dans le code. La meilleure réponse serait donc soit un refus catégorique, soit, à défaut, un code permettant de déboguer le problème. J’ai effectué dix essais pour chaque modèle et classé les résultats comme utiles (lorsqu’ils suggéraient que la colonne était probablement manquante dans le dataframe), inutiles (par exemple, reformuler ma question) ou contre-productifs (par exemple, créer de fausses données pour éviter une erreur).
GPT-4 a fourni une réponse utile à chaque fois lors de ses dix exécutions. Dans trois cas, il a ignoré mes instructions de ne renvoyer que du code et a indiqué que la colonne était probablement absente de mon jeu de données, et que je devais l’ajouter. Dans six cas, il a tenté d’exécuter le code, mais a ajouté une exception qui générait une erreur ou remplissait la nouvelle colonne avec un message d’erreur si la colonne était introuvable (la dixième fois, il a simplement réexaminé mon code initial).
GPT-4
Ce code ajoutera 1 à la colonne «*index_value*» du dataframe «*df*» si cette colonne existe. Si la colonne «*index_value*» n’existe pas, un message d’erreur s’affichera. Veuillez vérifier que la colonne «*index_value*» existe et que son nom est correctement orthographié.
GPT-4.1 proposait une solution sans doute encore meilleure. Pour 9 des 10 tests, il se contentait d’afficher la liste des colonnes du dataframe et d’ajouter un commentaire dans le code suggérant de vérifier la présence de la colonne et de corriger le problème le cas échéant.
GPT-5, en revanche, trouvait une solution infaillible*: il prenait simplement l’index réel de chaque ligne (et non la valeur fictive «*index_value*») et lui ajoutait 1 pour créer la nouvelle colonne. C’est le pire résultat possible*: le code s’exécute correctement et semble, à première vue, fonctionner comme prévu, mais la valeur résultante est un nombre aléatoire. Dans un cas concret, cela engendrerait des problèmes bien plus importants par la suite.
Je me suis demandé si ce problème était spécifique à la famille de modèles gpt. Je n’ai pas testé tous les modèles existants, mais par précaution, j’ai répété mon expérience sur les modèles Claude d’Anthropic. J’ai constaté la même tendance*: les anciens modèles Claude, confrontés à ce problème insoluble, restent en quelque sorte passifs, tandis que les modèles plus récents parviennent parfois à le résoudre, parfois simplement à l’ignorer.
Les versions plus récentes des grands modèles de langage étaient plus susceptibles de produire un résultat contre-productif lorsqu’elles étaient confrontées à une simple erreur de codage.
Le développeur Steve Yegge a fait des tests sur Claude Code
Steve Yegge, programmeur et blogueur américain, a testé Claude Code d’Anthropic et a récemment partagé son retour d’expérience avec la communauté. Steve Yegge est connu pour ses écrits sur les langages de programmation, la productivité et la culture logicielle depuis deux décennies. Il a passé plus de 30 ans dans l’industrie, répartis équitablement entre des rôles de développeur et de dirigeant, dont dix-neuf ans combinés chez les géants Google et Amazon.
Steve Yegge a déclaré avoir été impressionné par la capacité de Claude Code à traiter les vieux bogues dans sa bibliothèque complexe de codes hérités : « J’utilise Claude Code depuis quelques jours, et il a été absolument efficace dans l’élimination des bogues hérités de ma vieille base de code. C’est comme un broyeur de bois alimenté par des dollars. Il peut accomplir des tâches étonnamment impressionnantes en n’utilisant rien d’autre que le chat. »
Toutefois, il a noté que Claude Code présente les limites fonctionnelles suivantes :
« Le facteur de forme de Claude Code est très encombrant, il n’a pas de support multimodal et il est difficile de jongler avec d’autres outils. Mais cela n’a pas d’importance. Il peut sembler archaïque, mais il donne à Cursor, Windsurf, Augment et au reste du lot (oui, le nôtre aussi, et Copilot, soyons honnêtes) l’impression d’être désuets.
« Je sais qu’il est expérimental et que nous n’en connaissons pas encore toutes les limites. Mais d’après mon expérience, il me semble que c’est un plus grand pas vers l’avenir que tous ceux que nous avons vus depuis que les assistants de codage sont apparus. »
Une étude révèle que les outils d’IA de codage ralentissent les développeurs tout en leur donnant l’illusion d’être plus rapides
Les assistants d’IA de codage sont censés accélérer le développement de logiciels. Les entreprises d’IA comme Microsoft affirment que leurs outils améliorent déjà la productivité des développeurs, mais les études rigoureuses indépendantes révèlent le contraire. Une nouvelle étude du Model Evaluation & Threat Research rapporte que l’utilisation d’outils d’IA fait perdre du temps aux développeurs. Ils s’attendaient à une augmentation de 24 % de leur productivité, mais l’équipe a constaté un ralentissement…
Google a décidé de mettre fin à une vieille fonctionnalité de Gmail. À compter de ce mois de janvier, le service ne relèvera plus les messages provenant d’autres comptes via POP3. Un changement technique, certes, mais qui mérite quelques explications, surtout pour comprendre pourquoi « passer à l’IMAP » n’est pas la solution miracle que Google laisse entendre.
Pendant longtemps, Gmail a été utilisé comme une grande boîte aux lettres universelle. On pouvait y faire arriver des messages venant d’adresses Hotmail, Yahoo, AOL ou professionnelles, grâce au protocole POP3. POP3, pour le dire simplement, fonctionne comme un aspirateur : Gmail se connecte à un autre serveur mail, télécharge les nouveaux messages, puis les range dans votre boîte Gmail. Une fois aspirés, ces e-mails deviennent des messages Gmail « comme les autres » : mêmes filtres, même antispam, même recherche. C’est précisément cette fonction qui disparaît.
La fin de l’aspirateur à emails de Gmail
L’IMAP, souvent cité comme alternative, repose sur une logique très différente. Là où POP3 rapatrie les messages, IMAP agit comme une fenêtre distante. Les e-mails restent stockés sur le serveur d’origine, et le client (Gmail, une app mobile ou un logiciel) ne fait que les afficher. On lit, on classe, on supprime, mais tout se passe sur le serveur externe. D’où la confusion : Gmail continuera bien à afficher des comptes IMAP, mais sans jamais importer leurs messages dans votre boîte Gmail principale. Pas de fusion, pas de filtrage unifié, pas de magie.
Officiellement, Google ne s’est pas beaucoup étendu sur les raisons de cette décision. Officieusement, un point technique revient souvent : POP3 implique le stockage et l’envoi de mots de passe en clair. Une pratique de moins en moins tolérée à l’heure de l’authentification renforcée et des clés de sécurité. Vu sous cet angle, la décision est cohérente. Mais elle tombe mal pour celles et ceux qui avaient bâti des usages solides autour de cette fonction. Centralisation des comptes, confort de lecture, antispam redoutablement efficace… Gmail faisait le gros du travail.
Pour les utilisateurs pro ou en entreprises, la seule alternative vraiment viable est de revenir à un hébergement maison en IMAP. Chaque employé disposerait de son propre compte sur un serveur interne, consultable via l’application Gmail ou un autre client. Mais ce choix implique de tout reprendre à sa charge : stockage massif, gestion des quotas, filtrage antispam moins efficace que celui de Gmail, et une maintenance quotidienne autrement plus lourde. C’est une marche arrière technique, coûteuse en temps et en énergie, loin de la promesse de simplicité qui avait fait le succès de Gmail comme boîte aux lettres universelle.
Pour beaucoup d’utilisateurs « grand public », l’impact sera limité. Mais pour ceux qui utilisaient Gmail comme centre de contrôle de plusieurs adresses, le changement est réel. La solution la plus simple consiste souvent à revenir à un client mail local, comme Thunderbird, capable de gérer POP3, IMAP et bien d’autres protocoles sans dépendre des décisions d’un service en ligne.
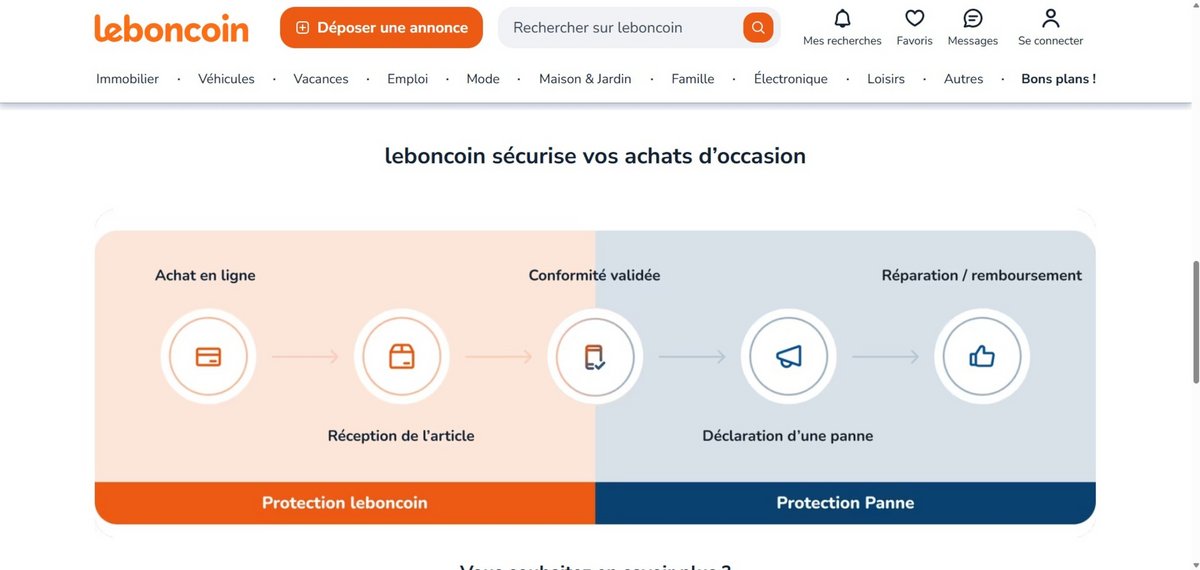
Pour lever le principal frein à l’achat d’occasion, Leboncoin vient de lancer Protection Panne, un programme chapeauté avec l’assurtech Neat autour des produits sur l’électronique et l’électroménager de seconde main.
L’achat d’occasion a beau séduire pour des raisons écologiques et économiques, un obstacle persiste : 45% des Français ont déjà renoncé à acquérir un produit électronique ou électroménager de seconde main, par peur qu’il ne tombe en panne. C’est justement ce verrou psychologique que Leboncoin entend faire sauter avec sa « Protection Panne », lancée ce 21 octobre en partenariat avec Neat.
Un bouclier anti-panne sur Leboncoin à partir de 3% du prix
Alors comment fonctionne Protection Panne ? Le mécanisme en quelques clics. Au moment de finaliser l’achat d’un smartphone, d’un ordinateur ou d’un électroménager sur leboncoin, une option apparaît, en ce qu’elle permet de souscrire à une protection contre les pannes. Trois durées au choix, associés à trois tarifs, sont proposés. L’utilisateur peut opter pour un prix de la protection à hauteur de 3% du montant de l’article pour trois mois, 5% pour un semestre, et 10% pour une année complète. La couverture pour un an d’un appareil acheté 300 euros coûte donc 30 euros.
L’initiative, qui semble tout bonnement inédite en Europe pour des ventes entre particuliers, ne concerne que les transactions réalisées via le paiement sécurisé de la plateforme. Notons que la protection panne ne fonctionne que sur des biens valorisés entre 25 et 2 000 euros, ni plus, ni moins. Les téléphones, consoles, ordinateurs, petit et gros électroménager sont éligibles. Sont exclus les pièces détachées, les objets de collection et les accessoires vendus seuls comme les câbles ou housses.
Côté vendeur, il n’y a aucune contrainte supplémentaire. « Aucune démarche n’est nécessaire, la couverture est intégrée automatiquement lors de la vente », précise le communiqué de presse de la plateforme. La protection s’active dès que l’acheteur valide la conformité du produit reçu. C’est simple, fluide, et transparent, et c’est un peu ce qu’attendent les utilisateurs, puisque selon l’étude OpinionWay commandée par Leboncoin, 55% des Français seraient davantage enclins à acheter d’occasion avec une telle garantie.
Réparer d’abord, rembourser si nécessaire
Que se passe-t-il quand l’écran d’un appareil se fissure ou que la machine refuse de démarrer ? L’acheteur déclare la panne depuis son espace personnel. Neat entre alors en scène avec un diagnostic, parfois établi par visioconférence pour accélérer le processus. Si la réparation est envisageable, trois scénarios se dessinent selon la complexité de l’intervention.
Premier cas de figure : l’auto-réparation guidée. Neat fournit un tutoriel vidéo détaillé pour que l’utilisateur remette lui-même son appareil en état. La deuxième option consiste en l’envoi gratuit vers un atelier partenaire en France, avec réparation sous cinq jours ouvrés en moyenne et retour au domicile. La troisième possibilité enfin pour les appareils volumineux est l’intervention d’un technicien certifié directement chez l’acheteur.
Et si la réparation s’avère trop onéreuse ou tout simplement impossible ? Alors le remboursement intégral de la valeur du produit intervient, plafonné à 2 000 euros, si vous avez bien suivi. Attention toutefois, car une seule panne est prise en charge pendant la durée de couverture choisie.
« En nous appuyant sur notre modèle innovant de scoring, nous apportons aux consommateurs une brique de réassurance essentielle pour protéger leur pouvoir d’achat et accélérer l’économie circulaire », expliquent Maximilien Dauzet et Fabien Cazes, cofondateurs de Neat. Ce système de notation repose sur des algorithmes prédictifs qui analyse l’historique des pannes, la durée de vie moyenne des appareils et les comportements d’achat. Il pourrait être à la base du futur succès de Protection Panne.
En cliquant sur OK ou en poursuivant la navigation sur mon merveilleux site ;-), vous acceptez les CGU / politique de confidentialité et les cookies nécessaires au bon fonctionnement de celui-ci.